Aula 42 – Redes Neurais Aplicadas a Chatbots: Explorando o Huggingface
Aula 42 – Redes Neurais Aplicadas a Chatbots: Explorando o Huggingface
Voltar para página principal do blog
Todas as aulas desse curso
Aula 41 Aula 43

TensorFlow – Keras – Redes Neurais

Pacote Programador Fullstack
Redes Sociais:
Site das bibliotecas
Tensorflow
Keras
Cursos Gratuitos
Digital Innovation
Quer aprender python3 de graça e com certificado? Acesse então:
workover
Meus link de afiliados:
Hostinger
Digital Ocean
One.com
Canais do Youtube
Toti
Lofi Music Zone Beats
Backing Track / Play-Along
Código Fluente
Putz!
Vocal Techniques and Exercises
Fiquem a vontade para me adicionar ao linkedin.
PIX para doações

PIX Nubank
Notebook da aula
Aula 42 – Redes Neurais Aplicadas a Chatbots: Explorando o Huggingface
Na aula passada vimos o Vicuna, um chatbot de código aberto apoiado por um conjunto de dados aprimorado e uma infraestrutura escalável e fácil de usar, e é inspirado pelo projeto Meta LLaMA e Stanford Alpaca.
Apresentamos o Vicuna Alpaca7B em um notebook do google colab pronto para usar.
O Vicuna é um modelo de linguagem treinado pela OpenAI, que serve como base para o Hugging Face, uma empresa que constrói e fornece ferramentas e bibliotecas de processamento de linguagem natural.
Nessa aula vamos explorar um pouco ele, o Huggingface.
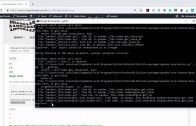
O Huggingface possui uma plataforma chamada “Model Hub” para compartilhar e baixar modelos pré-treinados de PLN e vários outros como: Text-to-Video, Text-to-Image, Image-to-Text, Depth Estimation, Image Classification, Object Detection…
Oobabooga
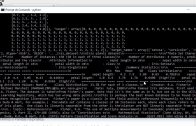
Vamos usar também o Oobabooga, que é um projeto de inteligência artificial (IA) de código aberto em desenvolvimento.
Ele é uma interface web de usuário, baseada no framework Gradio.
O Oobabooga permite a geração de texto em diferentes estilos, como notícias, ficção, poesia e código, com base em um prompt de entrada fornecido pelo usuário.
Além disso, ele oferece recursos de tradução de texto entre diferentes idiomas e é capaz de responder perguntas feitas pelos usuários.
O objetivo principal do Oobabooga é fornecer uma ferramenta para geração de conteúdo de alta qualidade, apoiada por modelos de linguagem poderosos, como LLaMA, GPT-J, Pythia, OPT e GALACTICA.
Embora ainda esteja em desenvolvimento, o Oobabooga já é utilizado para criar uma ampla variedade de conteúdos, como poemas, códigos, scripts, peças musicais, e-mails, entre outros.
Tendência
A tendência atual no campo de processamento de linguagem natural é o uso de modelos pré-treinados, como os disponíveis na plataforma do Hugging Face, em vez de criar modelos do zero.
Isso ocorre principalmente devido aos custos significativos associados ao desenvolvimento e treinamento de modelos grandes e complexos.
Ao utilizar modelos pré-treinados, os desenvolvedores podem aproveitar todo o conhecimento e capacidade de geração de texto desses modelos, economizando tempo e recursos que seriam necessários para desenvolver um modelo do zero.
Além disso, os modelos pré-treinados têm a vantagem de terem sido treinados em grandes conjuntos de dados e terem passado por um processo extensivo de ajuste fino, o que os torna mais eficazes em várias tarefas de processamento de linguagem natural.
No entanto, entender a parte técnica por trás desses modelos pré-treinados ainda é crucial.
Isso envolve estudar as arquiteturas subjacentes, como transformers, redes neurais recorrentes ou redes neurais convolucionais, e entender os detalhes de como esses modelos foram treinados e ajustados.
Isso inclui explorar as configurações de hiperparâmetros, tais como tamanho do modelo, tamanho do lote (batch size) e taxa de aprendizado, para obter os melhores resultados em diferentes tarefas.
Embora a utilização de modelos pré-treinados seja uma opção mais acessível e eficiente em termos de custo, é importante ter em mente que ainda requer recursos computacionais consideráveis para utilizá-los efetivamente.
O treinamento e a inferência com modelos grandes e complexos podem exigir recursos de hardware avançados, como unidades de processamento gráfico (GPUs) ou até mesmo unidades de processamento tensorial (TPUs), além de um tempo de execução considerável.
Em resumo, a tendência atual é aproveitar modelos pré-treinados, como os disponíveis no Hugging Face, devido ao custo envolvido no desenvolvimento e treinamento de modelos do zero.
No entanto, estudar a parte técnica por trás desses modelos é fundamental para aproveitar ao máximo seu potencial e obter resultados de alta qualidade em tarefas de processamento de linguagem natural.
Execução do Modelo em Produção
A execução de modelos pré-treinados muito grandes requer infraestrutura robusta e dimensionada adequadamente.
É preciso considerar recursos computacionais avançados, como GPUs ou TPUs, armazenamento suficiente e uma infraestrutura escalável para lidar com o processamento de dados.
A utilização de serviços de computação em nuvem pode ser uma opção viável para atender às demandas de infraestrutura necessárias para executar modelos grandes e complexos.