Aula 27 – Tensor Flow – Keras – Conjunto de dados CIFAR-10 – VGG 3 – Dropout
Aula 27 – Tensor Flow – Keras – Conjunto de dados CIFAR-10 – VGG 3 – Dropout
Voltar para página principal do blog
Todas as aulas desse curso
Aula 26 Aula 28 (Ainda não disponível)
Meu github:
https://github.com/toticavalcanti
Documentação oficial do TensorFlow:
https://www.tensorflow.org/
Quer aprender python3 de graça e com certificado? Acesse então:
https://workover.com.br/python-codigo-fluente

Python com Tensorflow
Se gostarem do conteúdo dêem um joinha 👍 na página do Código Fluente no
Facebook
https://digitalinnovation.one/
Aproveito para deixar meus link de afiliados:
Hostinger
Digital Ocean
One.com
Toti:
https://www.youtube.com/channel/UCUEtjLuDpcOvR3mIUr-viOA
Backing track / Play-along:
https://www.youtube.com/channel/UCT3TryVMqTqYBjf5g5WAHfA
Código Fluente
https://www.youtube.com/channel/UCgn-O-88XBAwdG9gUWkkb0w
Putz!
https://www.youtube.com/channel/UCZXop2-CECwyFYmHbhnAkAw
Fiquem a vontade para me adicionar ao linkedin.
Notebook da aula
PIX para doações

PIX Nubank
Se quiser copiar o código do PIX:
00020126580014BR.GOV.BCB.PIX013643c5f950-535b-4658-b91f-1f1d135fe4105204000053039865802BR5925Antonio Cavalcante de Pau6009SAO PAULO61080540900062070503***6304946B
Aula 27 – Tensor Flow – Keras – Conjunto de dados CIFAR-10 – VGG 3 – Dropout
CIFAR-10
Melhorando o Modelo
Agora que estabelecemos um ponto de partida, ou seja, a linha base (base line), a arquitetura VGG com três blocos, podemos investigar modificações nesse modelo e no algoritmo de treinamento para tentar melhorar o desempenho.
Vamos usar duas técnicas para isso, a regularização e o aumento de dados.
Técnicas de Regularização
Existem muitas técnicas de regularização que podemos tentar, embora a natureza do ajuste excessivo (Overfitting) observado sugira que talvez a parada precoce não seja apropriada e que as técnicas que diminuem a taxa de convergência podem ser úteis.
Por isso, analisaremos o efeito do abandono (Dropout) e da regularização do peso ou redução do peso.
Regularização Dropout
Dropout é uma técnica simples que elimina nós (neurônios) aleatoriamente da rede.
Ele tem um efeito de regularização, pois os nós restantes devem se adaptar para compensar o espaço dos nós removidos.
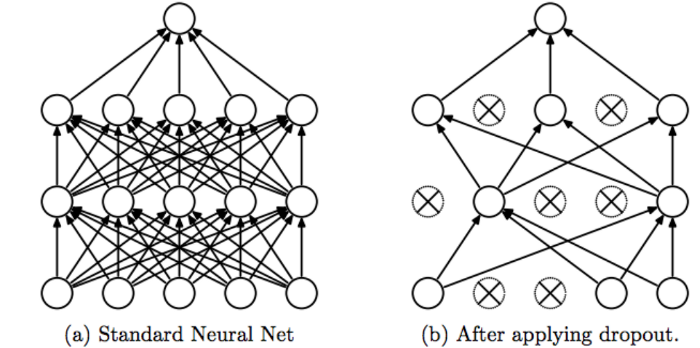
Dropout
O dropout força a rede neural a aprender recursos mais robustos que são úteis em conjunto com muitos subconjuntos aleatórios diferentes de outros neurônios.
Ele praticamente dobra o número de iterações necessárias para convergir.
No entanto, o tempo de treinamento para cada época é menor.
Com H unidades ocultas, cada uma das quais pode ser descartada, temos 2^H modelos possíveis.
Na fase de teste, toda a rede é considerada e cada ativação é reduzida por um fator p.
O dropout pode ser adicionado ao modelo, com novas camadas de dropout, onde a quantidade de nós removidos é especificada como um parâmetro.
Existem muitos padrões para adicionar Dropout a um modelo, em termos de onde adicionar no modelo as camadas e quanto dropout usar.
Nesse caso, adicionaremos camadas de dropout após cada camada de pooling máximo e após a camada totalmente conectada.
Usaremos uma taxa de exclusão fixa de 20% (por exemplo, reter 80% dos nós).
A definição do modelo base VGG 3 atualizado com dropout fica assim:
#bloco 1
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same', input_shape=(32, 32, 3)))
model.add(Conv2D(32, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
#bloco 2
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(64, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
#bloco 3
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(Conv2D(128, (3, 3), activation='relu', kernel_initializer='he_uniform', padding='same'))
model.add(MaxPooling2D((2, 2)))
model.add(Dropout(0.2))
model.add(Flatten())
model.add(Dense(128, activation='relu', kernel_initializer='he_uniform'))
model.add(Dropout(0.2))
model.add(Dense(10, activation=tf.nn.softmax, name='logits'))
OBS: Nesse exemplo, iremos treinar o modelo por 100 épocas, ao invés de 40 épocas, como fizemos nos exemplos anteriores, já que esperamos que o modelo continue a aprender acima das 20 épocas, que foi onde ele parou de aprender, sem o uso do dropout.
Agora acesse o notebook para rodar o código:
Notebook da aula
Truque para usar no colab
O Google Colab desconecta automaticamente o notebook se deixá-lo inativo por mais de 30 minutos. 🕑
Abra seu Chrome DevTools pressionando F12 ou ctrl + shift + i no Linux e insira o seguinte snippet de JavaScript em seu console:
function KeepClicking(){
console.log("Clicking");
document.querySelector("colab-connect-button").click()
}
setInterval(KeepClicking,60000)
Esta função faz um clique no botão de conexão a cada 60 segundos.
Assim, o Colab pensa que o notebook não está ocioso e você não precisa se preocupar em ser desconectado!
Desconexão durante a execução de uma tarefa
Ao se conectar a uma GPU, você recebe no máximo 12 horas por vez na máquina em nuvem.
Às vezes acontece de você ser desconectado, mesmo dentro desse lapso de tempo de 12 horas.
Conforme explicado nas Perguntas frequentes do Colab.
“O Colaboratory destina-se ao uso interativo. Cálculos de fundo de longa execução, especialmente em GPUs, podem ser interrompidos. ” 😕.
Anaconda
O código dessa aula, eu rodei o código usando meu processamento local, já que o colab impõe limites de processamento e tempo em seu plano free.
Para isso, usei o jupyter notebook do Anaconda, criei um ambiente chamado tensorflow, instalei tudo que precisamos nele: o jupyter, o CMD.exe, o matplotlib, o tensorflow, o tensorboard…
Antes de executar o notebook localmente
Antes de rodar o notebook localmente, no painel do anaconda:
Painel do Anaconda
Abra o prompt no ambiente que você criou, no meu caso, o ambiente tensorflow, e rode na pasta do notebook o seguinte comando:
tensorboard --logdir logs --port 6006
O comando acima cria a pasta logs na pasta do notebook, e é onde serão colocados os dados gerados durante o treinamento da rede, dados relativos a como a rede evoluiu durante o treinamento, baseado nas precisões nos dados de treino e validação.
É onde o tensorboard vai ler os dados para plotar os gráficos, e também definimos a porta como 6006.
OBS. Na aula https://www.codigofluente.com.br/aula-03-computacao-quantica-instalando-o-anaconda-e-o-qiskit/ de computação quântica, eu mostro como instalar o Anaconda.
Conclusão
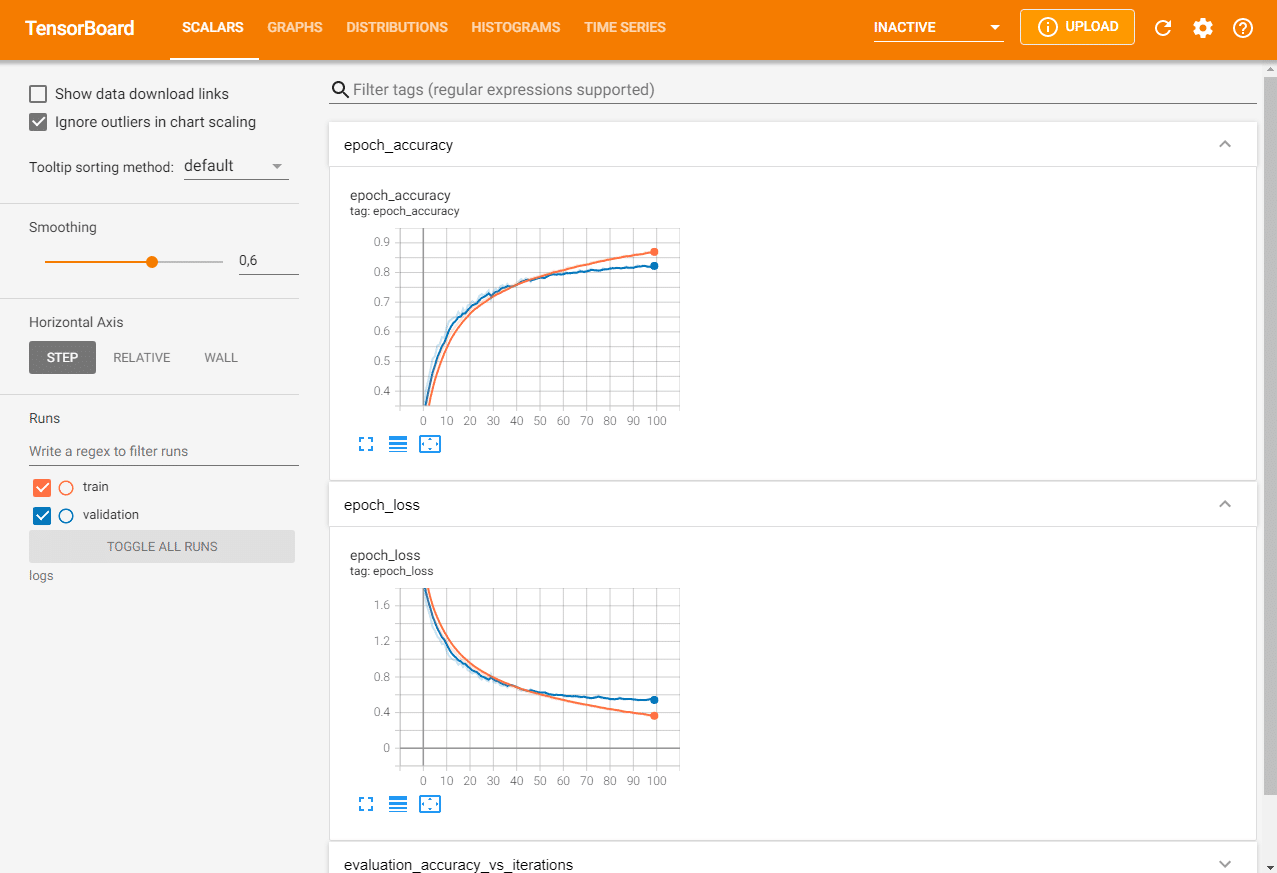
Saída do TensorBoard usando Dropout
Depois de testar o modelo, podemos ver um salto na precisão da classificação de cerca de 73% sem dropout para cerca de 87% com dropout.
Os resultados podem variar devido à natureza estocástica do algoritmo ou procedimento de avaliação, ou diferenças na precisão numérica.
Considere executar o exemplo algumas vezes e compare o resultado médio.
Revisando a curva de aprendizado do modelo, podemos ver que o overfitting foi resolvido.
O modelo converge bem por cerca de 40 ou 50 épocas, ponto em que não há nenhuma melhoria adicional no conjunto de dados de teste.
Este é um ótimo resultado.
Poderíamos elaborar este modelo e adicionar uma parada antecipada com em cerca de 10 épocas para salvar um modelo de bom desempenho no conjunto de teste durante o treinamento em um ponto em que nenhuma melhoria adicional seja observada.
Também poderíamos tentar explorar um cronograma de taxa de aprendizado que reduza a taxa de aprendizado após melhorias em cima do conjunto de teste.
Dropout tem apresentado um bom desempenho e não sabemos se a taxa escolhida de 20% é a melhor.
Poderíamos explorar outras taxas de dropout, bem como diferentes posicionamentos das camadas de dropout na arquitetura do modelo.
Por essa aula é só, na próxima, vamos explorar a regularização de peso, também conhecida como redução de peso (Weight Decay).
Voltar para página principal do blog
Todas as aulas desse curso
Aula 26 Aula 28 (Ainda não disponível)
Meu github:
https://github.com/toticavalcanti
Se gostarem do conteúdo dêem um joinha 👍 na página do Código Fluente no
Facebook
Link do código fluente no Pinterest
Novamente deixo meus link de afiliados:
Hostinger
Digital Ocean
One.com
Obrigado, até a próxima e bons estudos. 😉