Aula 02 – Instalando o Scikit learn
Instalando o Scikit-learn
Aprendizado de Máquina com Python e scikit-learn
Voltar para página principal do blog
Todas as aulas desse curso
Aula 01 Aula 03
45 degree lumbar bench extension Hamstring training clenbuterol for sale free download pdf owner’s manual for weslo wltl019060 home gym.
Link do meu Github com o script dessa aula:
Download do script da aula
As aulas são resenhas baseadas na documentação oficial do scikit-learn, disponível no endereço:
https://scikit-learn.org/stable/

Aprendizado de máquina com Scikit Learn
Antes de partir para prática, quero deixar meu link de afiliados na Hostinger, tá valendo a pena, dêem uma olhada: Hostinger
Dêem um joinha 👍 na página do Código Fluente no Facebook
Facebook
Meu link de referidos na digitalocean pra vocês.
Quem se cadastrar por esse link, ganha $100.00 dólares de crédito na digitalocean:
Digital Ocean
Esse outro é da one.com:
One.com
Instalando o scikit-learn
A maneira mais fácil de instalar o scikit-learn é usando PIP.
Abra um shell ou um cmd do windows e primeiro atualize o PIP com:
python -m pip install --upgrade pip
Agora sim, instale o scikit–learn:
python -m pip install scikit-learn
Ou, se estiver usando a IDE Anaconda, utilize:
conda install scikit-learn
Para fazer o upgrade do scikit-learn use.
python -m pip install -U scikit-learn
Ou, se estiver usando a IDE Anaconda, use:
conda update scikit-learn
Para desinstalar o scikit-learn digite.
python -m pip uninstall scikit-learn
Ou, se estiver usando a IDE Anaconda, utilize:
conda remove scikit-learn
Vamos conhecer um pouco sobre a base de dados íris que vem com o scikit-learn.
Além do íris, o scikit-learn vem também com a base de dígitos manuscritos, que falamos na aula passada e com o preços de casas em Boston para exemplo de uso de regressão.
A base de dados íris, é um conjunto multivalorado introduzido pelo estatístico e biólogo britânico Ronald Fisher em seu artigo de 1936.
Ele usou múltiplas medições em problemas taxonômicos, como um exemplo de análise discriminante linear.
É chamado também de conjunto de dados de Anderson, porque Edgar Anderson coletou os dados para quantificar a variação morfológica das íris de flores de três espécies relacionadas.
Duas das três espécies foram coletadas na Península de Gaspé “todas do mesmo pasto e colhidas no mesmo dia e medidas ao mesmo tempo pela mesma pessoa com o mesmo aparelho”.
O conjunto de dados consiste em 150 amostras de cada uma das 3 espécies de íris (Íris setosa, Íris virgínica e Íris versicolor).
Quatro características foram medidas a partir de cada amostra: o comprimento e a largura das sépalas e pétalas, em centímetros.
Sépalas são peças da flor, situada no verticilo mais externo dela.
Pétalas são peças constituintes da flor, situadas no seu verticilo protetor mais interno.
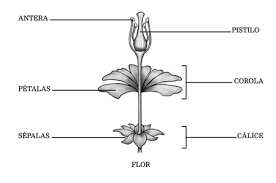
íris -Sépala -Pétala 01

íris -Sépala -Pétala 02
Com base na combinação dessas quatro características, Fisher desenvolveu um modelo discriminante linear para distinguir as espécies umas das outras.
Com base no modelo discriminante linear de Fisher, esse conjunto de dados tornou-se um caso de teste típico para muitas técnicas de classificação estatística em aprendizado de máquina, como máquina de vetores de suporte (SVM, do inglês: support vector machine).
No entanto, o uso desse conjunto de dados na análise de cluster não é comum, pois o conjunto de dados contém apenas dois clusters com separação bastante óbvia.
Um dos grupos contém Iris setosa, enquanto o outro grupo contém Iris virgínica e Iris versicolor e não é separável sem a informação de espécies que Fisher utilizou.
Isso torna o conjunto de dados um bom exemplo para explicar a diferença entre técnicas supervisionadas e não supervisionadas na mineração de dados: o modelo discriminante linear de Fisher só pode ser obtido quando as espécies objeto são conhecidas: rótulos e aglomerados de classes não são necessariamente os mesmos.
Vamos abrir um interpretador Python e, em seguida, carregar os conjuntos de dados da íris e dos dígitos.
No cmd ou no shell digite python, ou abra sua IDE preferida (PyCharm, Anaconda, etc).
Explorando a base
Vamos importar o sklearn:
from sklearn import datasets
Agora vamos carregar a base de dados das íris de flores:
iris = datasets.load_iris()
type(iris)
Saída: <class ‘sklearn.utils.Bunch’>
Dê uma primeira olhada nos dados:
print(iris.data)
Cada linha é uma observação (também conhecida como: amostra, exemplo, instância, registro)
Cada coluna é um recurso (também conhecido como: feature, preditor, atributo, variável independente, entrada, regressor, covariável).
Imprima os nomes dos quatro recursos (features)
print(iris.feature_names)
Ou simplesmente retire o print, vai funcionar da mesma forma:
iris.feature_names
Saída: [‘sepal length (cm)’, ‘sepal width (cm)’, ‘petal length (cm)’, ‘petal width (cm)’]
Liste as classes alvo da classificação.
list(iris.target_names)
O comando a seguir imprime inteiros representando as espécies de cada observação: 0, 1 e 2 representam espécies diferentes.
print(iris.target)
Ou simplesmente retire o print, ele é totalmente disnpensável nesses casos:
iris.target
Verifique os tipos de recursos e resposta:
print(type(iris.data))
print(type(iris.target))
Saída:
<class ‘numpy.ndarray’>
<class ‘numpy.ndarray’>
Verifique o formato das features ( primeira dimensão = número de observações, segunda dimensão = número de features )
print(iris.data.shape)
Saída:
(150, 4)
Ou seja, 150 registros e 4 variáveis(features), no caso, características das pétalas e sépalas das flores.
Verifique o formato da resposta (dimensão única correspondente ao número de observações)
print(iris.target.shape)
Saída:
(150, )
Armazena a matriz de recurso (feature) em “x”
x = iris.data
Armazena o vetor de resposta em “y”
y = iris.target
Na próxima aula continuaremos a explorar o base de dados das íris.
Voltar para página principal do blog
Todas as aulas desse curso
Aula 01 Aula 03
Link do meu Github com o script dessa aula:
Download do script da aula
Esse são meus link de afiliados na Hostinger: Hostinger
Curta a página do Código Fluente no Facebook
https://www.facebook.com/Codigofluente-338485370069035/
Meu link de referidos na digitalocean .
Quem se cadastrar por esse link, ganha $100.00 dólares de crédito na digitalocean:
Digital Ocean
E o da one.com:
One.com
Obrigado, até a próxima e bons estudos. 😉