Curso de Data Science
Aula 03 – Data Science – R – Caso do Titanic – Kaggle

Caso do Titanic – Kaggle
Continuando com o problema do Titanic proposto pelo Kaggle.
A ideia agora é juntar os dois conjuntos ( titanic.train e titanic.test) em uma variável titanic.full, mas para poder fazer isso, é preciso criar um campo nos dois conjuntos, de forma que se consiga identificar no conjunto titanic.full, quem era originalmente do titanic.train e quem era do titanic.test.
Porque juntar os conjuntos?
Porque se eu quiser por exemplo, pegar uma mediana da idade, de tarifa do bilhete, etc. Será mais confiável uma mediana que abranja todos os registros, do que uma mediana que só considere parte de um conjunto total.
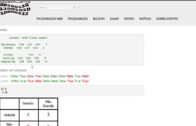
Então para fazer esse conjunto total, titanic.full, será criado adicionado o campo IsTrainSet com valor boolean TRUE para todos os registros do titanic.train e com valor FALSE para todos os registros do titanic.test, antes de juntá-los.
#Define IsTrainSet como TRUE se o elemento for do train.csv
titanic.train$IsTrainSet
#Define IsTrainSet como FALSE se o elemento não for do train.csv
titanic.test$IsTrainSet
Outra coisa também é criar o campo Survived no titanic.test e atribuir o valor NA a todos os registros, mas isso será na próxima aula.