Aula 04 – Tensor Flow – Redes Neurais – TensorFlow Playground
Aula 04 – Tensor Flow – Redes Neurais – TensorFlow Playground
Voltar para página principal do blog
Todas as aulas desse curso
Aula 03 Aula 05
Meu github:
https://github.com/toticavalcanti
Documentação oficial do TensorFlow:
https://www.tensorflow.org/
Link para o notebook da aula:
notebook-da-aula

Python com Tensorflow
Se gostarem do conteúdo dêem um joinha 👍 na página do Código Fluente no
Facebook
Link do código fluente no Pinterest
Aproveito para deixar meus link de afiliados:
Hostinger
Digital Ocean
One.com
Aula 04 – Tensor Flow – Redes Neurais – TensorFlow Playground
Antes de descer pro play
Vamos entender melhor alguns termos usados em redes neurais e no TensorFlow Playground
Época
Uma passada de todos os exemplos de treinamento na rede, para frente e uma para trás (backpropagation) para ajustar os pesos dos nós.
Tamanho do lote
Número de exemplos de treinamento em uma passada ida e volta na rede.
Quanto maior o tamanho do lote, mais espaço de memória será necessário.
Número de iterações
Número de passadas idas e voltas na rede, cada passada usando o número de exemplos [tamanho do lote].
Se você tiver 1000 exemplos de treinamento e seu tamanho de lote for 500, serão necessárias duas iterações para concluir uma época.
Taxa de Aprendizagem
Determina a velocidade do aprendizado.
Redes neurais de aprendizado profundo são treinadas usando o algoritmo de descida gradiente estocástico.
Ou seja, depende de variáveis aleatórias.
A descida gradiente estocástica é um algoritmo de otimização que estima o gradiente de erro para o estado atual do modelo, usando exemplos do conjunto de dados de treinamento, e em seguida, atualiza os pesos do modelo usando o algoritmo de retropropagação de erros, conhecido como retropropagação simples.
A quantidade de atualização dos pesos durante o treinamento é chamado de taxa de aprendizado.
Regularização
Serve para previnir o overfitting ou superajuste, que é quando a rede fica muito especializada nos dados de treinamento, você pode imaginar como se ela decorasse os resultados corretos que tem nos dados de treino, mas, quando recebe novos dados, dados que ela não conhece, ela se sai mal, ela perdeu a generalização.
São fornecidos dois tipos: L1 e L2.
A L1 é mais indicada em casos que se tenha dados de features esparços, onde é necessário selecionar alguns em muitas opções.
Então, a L1 vai selecionar essas poucas features e atribuir pesos altos a elas, e as demais, as que não foram selecionadas por ela, um peso baixo ou zero.
A L2 é indicada para quando se tem entradas correlacionadas, e o que determina o peso que ela vai atribuir as conexões dos neurônios, é o nível de correlacionamento.
Quanto maior o Regularization Rate, menor é o range dos pesos.
Data
É a parte onde você escolhe o tipo de distribuição dos dados pra testar a rede.
As opções para classificação são: Círculo, Gaussiano, Ou exclusivo e Espiral.
E para regressão: Plano e Multi Gaussiano.
Features
São as características dos dados que a rede usará pra fazer seu trabalho de classificação ou regressão, podemos dizer que features são as entradas.
Camadas ocultas
Aumenta e diminue o número de camadas ocultas.
Também pode selecionar os neurônios para cada camada oculta e experimentar diferentes camadas e neurônios ocultos e verificar como os resultados estão mudando.
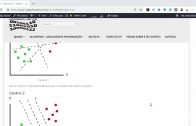
Agora sim, vamos explorar o playground.
https://playground.tensorflow.org/
Ficamos por aqui e até a próxima.
Voltar para página principal do blog
Todas as aulas desse curso
Aula 03 Aula 05
Meu github:
https://github.com/toticavalcanti
Se gostarem do conteúdo dêem um joinha 👍 na página do Código Fluente no
Facebook
Link do código fluente no Pinterest
Novamente deixo meus link de afiliados:
Hostinger
Digital Ocean
One.com
Obrigado, até a próxima e bons estudos. 😉