Aula 06 – Scikit-Learn – Algoritmo dos vizinhos mais próximos KNN
K – Nearest Neighbours (KNN), algoritmo dos vizinhos mais próximos
Voltar para página principal do blog
Todas as aulas desse curso
Aula 05 Aula 07
Link do meu Github com o script dessa aula:
Download do script da aula
Link da documentação oficial do Sklearn:
https://scikit-learn.org/stable/

algoritmo dos vizinhos mais próximos KNN
Se gostarem do conteúdo dêem um joinha 👍 na página do Código Fluente no
Facebook
Link do código fluente no Pinterest
Meus links de afiliados:
Hostinger
Digital Ocean
One.com
Na aula passada vimos o Pandas, mas, não falei sobre a estrutura Panel.
Ao elaborar as aulas referentes ao Pandas, vi que quando tentamos criar um Panel, o Pandas dá o seguinte recado:
Panel is deprecated and will be removed in a future version.
The recommended way to represent these types of 3-dimensional data are with a MultiIndex on a DataFrame, via the Panel.to_frame() method
Alternatively, you can use the xarray package http://xarray.pydata.org/en/stable/.
Pandas provides a `.to_xarray()` method to help automate this conversion.
Ou seja, o Panel foi descontinuado, ainda funciona, mas, nas próximas versões do Pandas ele não existirá mais.
Para esse curso, isso é irrelevante, já que vamos usar apenas DataFrames e Series.
K – Nearest Neighbours (KNN), algoritmo dos vizinhos mais próximos
sklearn.neighbours fornece funcionalidade para métodos de aprendizado supervisionados e não supervisionados baseados em vizinhos .
O aprendizado supervisionado baseado em vizinhos são de dois tipos:
- Classificação de dados com rótulos discretos
- Regressão para dados com rótulos contínuos.
Os não supervisionados são a base de muitos outros métodos de aprendizado, principalmente o aprendizado múltiplo e o agrupamento espectral (manifold learning and spectral clustering).
Apesar de sua simplicidade, os vizinhos mais próximos obtiveram sucesso em um grande número de problemas de classificação e regressão, incluindo dígitos manuscritos ou cenas de imagens de satélite.
Sendo um método não paramétrico, muitas vezes é bem sucedido em situações de classificação onde o limite de decisão é muito irregular.
Os modelos k-NN funcionam pegando um ponto de dados e observando os “k” pontos de dados rotulados mais próximos.
Então, a um novo ponto de dado é atribuído ao rótulo da maioria dos pontos mais próximos dele, isto é, do “k“.
Vamos pegar um caso simples para entender esse algoritmo.
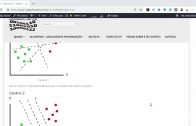
A seguir, uma distribuição de círculos vermelhos (Red Circle – RC) e quadrados verdes (Green Square – GS):
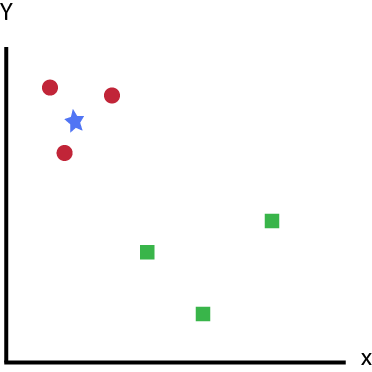
k-NN – Nearest Neighbors – Vizinhos – distribuição de círculos vermelhos (Red Circle – RC) e quadrados verdes (Green Square – GS)
Você pretende descobrir a classe da estrela azul (Blue Star – BS).
BS pode ser RC ou GS e nada mais.
O “K” é usado no algoritmo KNN para encontrar os k vizinho mais próximo da estrela azul.
Digamos que K = 3.
Assim, agora faremos um círculo com o BS com o centro tão grande que inclua apenas três pontos de dados no plano. Veja a imagem a seguir:

k-NN – Nearest Neighbors – Vizinhos – Seleção com k = 3
Os três pontos mais próximos da Blue Star – BS são todos Red Circle – RC.
Assim, com um bom nível de confiança, podemos dizer que o BS deve pertencer à classe RC.
Aqui, a escolha ficou muito óbvia, pois todas as três possibilidades dos vizinhos mais próximos foram RC.
A escolha do parâmetro K é muito crucial neste algoritmo.
Se aumentar o k, vai abranger uma região maior de vizinhos, veja a figura abaixo.

k-NN – Nearest Neighbors – Vizinhos – k =6
A distância pode, em geral, ser qualquer medida métrica: a distância euclidiana padrão é a escolha mais comum.
Distância Euclidiana
Primeira análise do Iris Dataset
Em uma primeira análise do iris dataset, deu para notar que setosas possuem pétalas pequenas, versicolor tem pétalas de tamanho médio e virgínica tem as maiores pétalas.
Além disso, as setosas parecem ter sépalas mais curtas e mais largas do que as outras duas classes.
Legal né?
Mesmo sem usar um algoritmo de machine learning, conseguimos construir intuitivamente um classificador que pode ter um bom desempenho no conjunto de dados.
Mãos a obra. 😉
Usaremos o scikit-learn para treinar um classificador KNN e avaliar seu desempenho no conjunto de dados usando o padrão de modelagem em 4 etapas:
- Importar o algoritmo de aprendizado
- Instanciar o modelo
- Ensinar ao modelo
- Prever a resposta
O scikit-learn exige que a matriz x e o vetor de destino sejam matrizes numpy.
Além disso, precisamos dividir nossos dados em conjuntos de treinamento e teste.
O código a seguir faz exatamente isso.
Como já instalamos o pandas, podemos fazer o import sem problemas:
#Importa os datasets que vem com o scikit learn
from sklearn import datasets
import pandas as pd
iris = datasets.load_iris()
irs = pd.DataFrame(iris.data, columns = iris.feature_names)
irs['class'] = iris.target
irs.head()
Saída:
O .head() exibe as colunas e as 5 primeiras linhas do conjunto de dados, caso queira imprimir mais linhas ou menos é só passar o número como parâmetro.
Para imprimir todas colunas do conjunto de dados use:
irs.columnsSe quiser saber quantas linhas tem a base de dados, use o método count():
irs.count()As classes em sklearn.neighbors podem manipular arrays Numpy ou scipy.sparse como entrada.
Para matrizes densas, um grande número de possíveis métricas de distância é suportado.
Para análise de dados, precisamos muitas vezes de informações estatísticas da base de dados.
Por exemplo: desvio padrão, média, valor mínimo e máximo de colunas, etc.
Com o pandas é fácil de fazer, use o método describe():
irs.describe()
Saída:
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) CLASS
count 150.000000 150.000000 150.000000 150.000000 150.000000
mean 5.843333 3.057333 3.758000 1.199333 1.000000
std 0.828066 0.435866 1.765298 0.762238 0.819232
min 4.300000 2.000000 1.000000 0.100000 0.000000
25% 5.100000 2.800000 1.600000 0.300000 0.000000
50% 5.800000 3.000000 4.350000 1.300000 1.000000
75% 6.400000 3.300000 5.100000 1.800000 2.000000
max 7.900000 4.400000 6.900000 2.500000 2.000000
Vamos ao NearestNeighbours? 😉
Para modelar os dados, vamos fazer alguns pré-processamentos.
Pré-processamento
O próximo passo é dividir nosso conjunto de dados em seus atributos e rótulos.
O x recebe sepal length (cm), sepal width (cm), petal length (cm) e petal width (cm) e o y recebe os rótulos, isto é, as classes de cada flor (0, 1 e 2).
Em outras palavras, a variável x contém as quatro primeiras colunas do conjunto de dados (isto é, atributos), enquanto y contém os rótulos.
Para fazer isso, use o seguinte código:
x = irs.iloc[:, :-1].values
y = irs.iloc[:, 4].values
Divisão em conjunto de teste e de treino
Para evitar o ajuste excessivo, dividiremos nosso conjunto de dados em duas partes, uma para treinamento e outra para teste e avaliar o modelo.
Desta forma, nosso algoritmo é testado em dados não vistos, como seria em uma aplicação em produção.
Para criar as divisões de treinamento e teste, execute o seguinte script:
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.20)
O script acima, divide o conjunto de dados em 80% de dados de treino e 20% de dados de teste.
Isso significa que, do total de 150 registros, o conjunto de treinamento conterá 120 registros e o conjunto de testes conterá 30 registros.
Feature Scaling (Valores das features na mesma escala)
Trabalhar com dados em escalas diferentes pode ser um problema que pode prejudicar os resultados de algoritmos de Machine Learning.
Por isso, antes de fazer qualquer previsão real, é sempre uma boa prática escalar os recursos para que todos possam ser uniformemente avaliados. Wikipedia explica bem o raciocínio:
Como o intervalo de valores dos dados brutos varia amplamente, em alguns algoritmos de aprendizado de máquina, as funções objetivas não funcionarão adequadamente sem a normalização. Por exemplo, a maioria dos classificadores calcula a distância entre dois pontos pela distância euclidiana. Se um dos recursos tiver um amplo intervalo de valores, a distância será regida por esse recurso específico. Portanto, o intervalo de todos os recursos deve ser normalizado para que cada recurso contribua aproximadamente proporcionalmente à distância final.
O algoritmo de descida de gradiente (gradient descent algorithm), que é usado em treinamento de redes neurais e outros algoritmos de aprendizado de máquina, também convergem mais rápido com recursos normalizados.
Normalização
A maioria dos algoritmos de Machine Learning assumem que os dados estão padronizados na hora de construir o modelo, isto é, assumem que os dados estão todos na mesma escala.
Sem isso alguns algoritmos terão uma performance ruim gerando modelos ineficientes.
Um exemplo disso são os algoritmos baseados em cálculos de distância.
O pacote preprocessing da Scikit-Learn tem algumas funções de padronização como a StandardScaler().
O StandardScaler() ignora a forma da distribuição e transforma os dados para forma com média próxima de zero e um desvio padrão próximo a um.
A distribuição normal com média zero (nula) e desvio padrão unitário é chamada de distribuição normal centrada e reduzida ou de distribuição normal padrão.
Lembrando que o desvio padrão é a medida de dispersão em torno da média, ele diz qual é a variação dos dados em torno da média.
A distribuição normal é uma das mais importantes distribuições da estatística, ela é conhecida também como distribuição de Gauss ou Gaussiana.
Voltando ao iris dataset, o script a seguir executa o redimensionamento das features, que são as medidas das pétalas e sépalas das flores.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(x_train)
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test)
O método fit() calcula a média e o desvio padrão da distribuição para fazer a padronização dos dados.
E método transform() aplica os cálculos para fazer a transformação nos dados.
Treinamento e Previsões
É extremamente simples treinar o algoritmo KNN e fazer previsões com ele, especialmente ao usar o Scikit-Learn.
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors = 5)
classifier.fit(x_train, y_train)
Na primeira linha importamos a classe KNeighborsClassifier da biblioteca sklearn.neighbors.
Na segunda, a classe é inicializada com um parâmetro, ou seja, n_neigbours igual a 5.
Este é basicamente o valor para o K.
Não existe um valor ideal para K e ele é selecionado após o teste e a avaliação, entretanto, para começar, 5 parece ser o valor mais comumente usado para o algoritmo KNN.
O passo final é fazer previsões sobre os dados de teste.
Para isso, execute o seguinte script:
y_pred = classifier.predict(x_test)
Avaliando o Algoritmo
Para avaliar um algoritmo, a matriz de confusão, a precisão, o recall e a pontuação f1 são as métricas mais utilizadas.
Os métodos confusion_matrix e classification_report do sklearn.metrics podem ser usados para calcular essas métricas.
Dê uma olhada no seguinte script:
from sklearn.metrics import classification_report, confusion_matrix
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
Saída:
[[10 0 0]
[ 0 11 1]
[ 0 0 8]]
precision recall f1-score support
0 1.00 1.00 1.00 10
1 1.00 0.92 0.96 12
2 0.89 1.00 0.94 8
micro avg 0.97 0.97 0.97 30
macro avg 0.96 0.97 0.97 30
weighted avg 0.97 0.97 0.97 30
Os resultados mostram que o nosso algoritmo KNN foi capaz de classificar todos os 30 registros no conjunto de testes com quase 100% de precisão, o que é excelente.
Agora vamos ajustar para 9 o n_neighbors = 9 e ver se o resultado muda.
classifier = KNeighborsClassifier(n_neighbors = 9)
classifier.fit(x_train, y_train)
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
Saída:
[[10 0 0]
[ 0 12 0]
[ 0 0 8]]
precision recall f1-score support
0 1.00 1.00 1.00 10
1 1.00 1.00 1.00 12
2 1.00 1.00 1.00 8
micro avg 1.00 1.00 1.00 30
macro avg 1.00 1.00 1.00 30
weighted avg 1.00 1.00 1.00 30Agora ficou com 100% de precisão.
Embora o algoritmo tenha funcionado muito bem com esse conjunto de dados, não espere os mesmos resultados com novas amostras.
Como observado anteriormente, o KNN nem sempre funciona tão bem com recursos de alta dimensionalidade ou categóricos.
Vimos então, como implementar K-Nearest Neighbours com scikit-learn.