Aula 07 – Scikit-Learn – Taxa de erros no KNN
Scikit-Learn – Taxa de erros no KNN
Comparando a taxa de erros com o valor K no KNN
Voltar para página principal do blog
Todas as aulas desse curso
Aula 06 Aula 08
Link do meu Github com o script dessa aula:
Download do script da aula
Link da documentação oficial do Sklearn:
https://scikit-learn.org/stable/

Taxa de erros no KNN
Se gostarem do conteúdo dêem um joinha 👍 na página do Código Fluente no
Facebook
Link do código fluente no Pinterest
Meus links de afiliados:
Hostinger
Digital Ocean
One.com
Na seção de treinamento e previsão, dissemos que não há como saber de antemão qual valor de K produz os melhores resultados.
Nós escolhemos aleatoriamente 5 como o valor de K, e em uma primeira tentativa não teve 100% de acertividade, depois mudamos para 9 e aí o resultado foi 100%.
Como as amostras são escolhidas aleatoriamente na divisão de conjunto de treino e de teste, durante o teste na aula, mesmo com o K = 5, o resultado foi 100%.
Por isso, o ideal é testar vários valores para K e ver qual é o que produz o melhor resultado.
Vamos a um script que testa valores para K de 1 até 40.
Antes vamos importar o dataset, o pandas e construir o dataframe.
#Importa os datasets que vem com o scikit learn
from sklearn import datasets
#importa a biblioteca pandas como pd
import pandas as pd
iris = datasets.load_iris()
irs = pd.DataFrame(iris.data, columns = iris.feature_names)
irs['class'] = iris.targetDivida o conjunto de dados em seus atributos e rótulos.
x = irs.iloc[:, :-1].values
y = irs.iloc[:, 4].values
Crie as divisões de treinamento e teste:
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.20)
Redimensione as features.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(x_train)
x_train = scaler.transform(x_train)
x_test = scaler.transform(x_test) Agora sim, vamos calcular a média de erro para todos os valores previstos, onde K varia de 1 até 40.
#importa o numpy como np
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
error = []
# Calculando erro para valores de K entre 1 e 40
for i in range(1, 40):
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(x_train, y_train)
pred_i = knn.predict(x_test)
error.append(np.mean(pred_i != y_test))
O script acima executa um loop de 1 a 40.
Em cada iteração, o erro médio dos valores previstos do conjunto de teste é calculado e o resultado é anexado à lista de erros.
O próximo passo é plotar os valores de erro em relação aos valores de K.
Execute o seguinte script para plotar o gráfico:
#importa o matplotlib como plt
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 6))
plt.plot(range(1, 40), error, color='red', linestyle='dashed', marker='o',
markerfacecolor='blue', markersize=10)
plt.title('Error Rate K Value')
plt.xlabel('K Value')
plt.ylabel('Mean Error')
#Para mostrar o gráfico
plt.show()
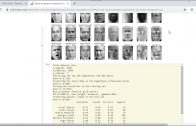
O gráfico de saída
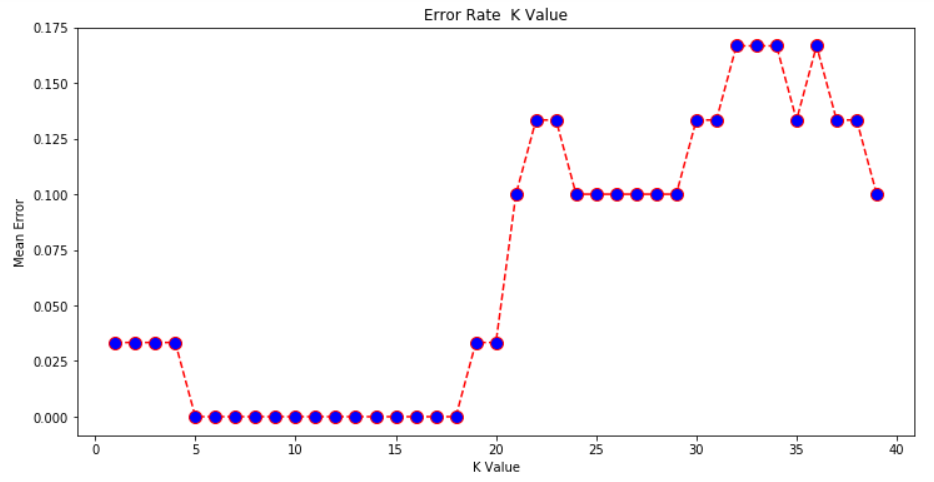
Olhando a saída, podemos ver que o erro médio é zero quando o valor do K está entre 5 e 18.
Façam testes com o valor de K para ver como isso afeta a precisão das previsões.
Conclusão
KNN é um algoritmo de classificação simples, mas poderoso.
Não requer treinamento para fazer previsões, que é tipicamente uma das partes mais difíceis de um algoritmo de aprendizado de máquina.
O algoritmo KNN tem sido amplamente utilizado para encontrar similaridade de documentos e reconhecimento de padrões.
Também tem sido empregado para desenvolver sistemas de recomendação e para redução de dimensionalidade em etapas de pré-processamento para visão computacional, particularmente tarefas de reconhecimento facial.
Tentem implementar o algoritmo KNN em outro conjunto de dados diferente.
Varie o tamanho do teste e do treinamento junto com o valor K para ver como seus resultados diferem e como você pode melhorar a precisão do seu algoritmo.