Aula 16 – Hadoop – Tutorial Apache Pig
Aula 16 – Hadoop – Tutorial Apache Pig

Apache Pig
Aula anterior Próxima aula
Página principal
Se gostarem do conteúdo dêem um joinha 👍 na página do Código Fluente no
Facebook
Esse é o link do código fluente no Pinterest
Meus links de afiliados:
Hostinger
Digital Ocean
One.com
Apache Pig
Documentação oficial: http://pig.apache.org/
Lembrando que nas aulas do curso para certificação hortonworks para hadoop aqui do código fluente, tem algumas aulas práticas usando o Pig.
Quem quiser conferir é só clicar no link: https://www.codigofluente.com.br/big-data/certificacao-hortonworks-hadoop/
História
O Pig surgiu como um projeto de pesquisa do Yahoo no ano de 2006, ele foi desenvolvido para criar e executar tarefas MapReduce em grandes conjuntos de dados.
Em 2007, o Apache Pig foi aberto, e em 2008 foi feito o primeiro lançamento do Apache Pig.
Em 2010, o Apache Pig tornou-se um projeto de alto nível da Apache.
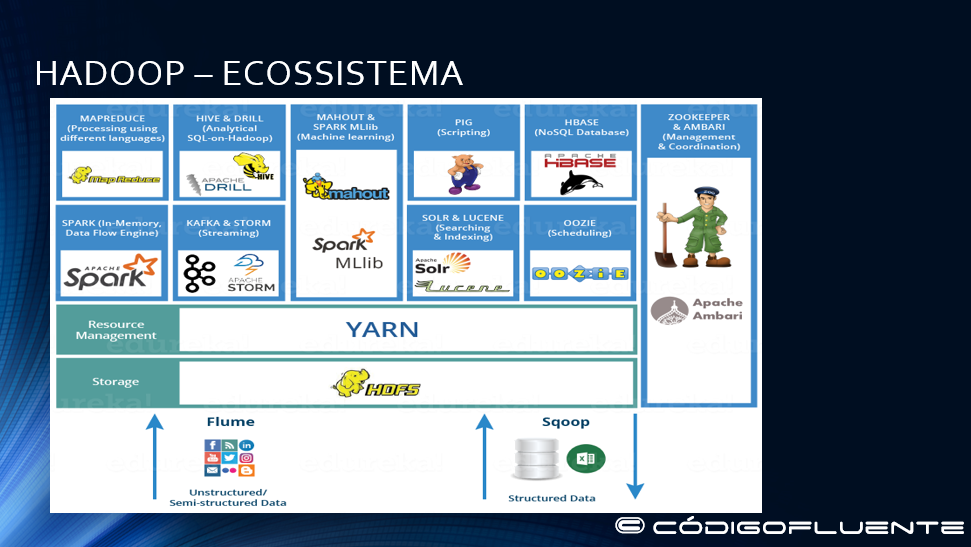
Ecossistema Hadoop Ambari – Hortonworks
Introdução
O que é, e para que serve o Apache Pig?
O Apache Pig é uma abstração do MapReduce.
É uma ferramenta / plataforma usada para analisar conjuntos maiores de dados, representando-os como fluxos de dados.
Geralmente usado com o Hadoop
Podemos realizar todas as operações de manipulação de dados no Hadoop usando o Apache Pig.
A propriedade mais importante do Pig é a paralelização, sua estrutura foi totalmente pensada para trabalhar com isso, o que por sua vez, permite a manipulação de conjuntos de dados muito grandes.
Ele permite que os profissionais de dados gravem transformações de dados complexas sem saber Java a fundo.
Pig Latin
A linguagem de script é simples, semelhante a SQL e é chamada Pig Latin, e tem agradado aos desenvolvedores já familiarizados com linguagens de script e SQL.
Pig é completo, por isso, você pode fazer todas as manipulações de dados necessárias nele.
Através do recurso user-defined function (UDF), ele pode invocar códigos em muitas linguagens como JRuby, Jython e Java.
Você também pode incorporar scripts Pig em outras linguagens.
Projetos grandes e complexos
Você pode usar o Pig como um componente para construir aplicativos maiores e mais complexos que resolvam problemas reais de negócios.
Fontes de dados
Ele trabalha com dados de várias fontes, incluindo dados estruturados e não estruturados, armazenando os resultados no Hadoop Data File System.
Os scripts Pig são traduzidos em uma série de tarefas MapReduce que são executadas no cluster do Apache Hadoop.
Instalação
Não vou falar sobre a instalação do Pig, porque nesse tutorial estamos usando a máquina virtual cloudera, que já tem o Pig instalado e configurado.
Em algum momento futuro eu quero fazer um tutorial mostrando como instalar e configurar um ecosistema Hadoop do zero em uma distribuição linux e aí sim, mostrar como instalar e configurar as variáveis de ambiente, não só o Pig, mas várias ferramentas que trabalham com o hadoop file system.
Nessa parte de infra, existem facilidades como o uso de máquinas virtuais já prontas e configuradas como essa da cloudera que estamos usando, tem também uma versão docker dessa mesma máquina cloudera, tem a máquina da hortonworks entre outros fabricantes, existem também containers docker para hadoop e o Kubernetes para a orquestração de containers, enfim, várias opções de ferramentas para deploy automatizado da infraestrutura de um clusters Hadoop.
Outra possibilidade é você mesmo criar sua máquina instalando e configurando os componentes que quiser em uma distribuição linux da sua escolha.
Seguindo!
Por que precisamos do Apache Pig?
Programadores que não são tão bons em Java normalmente costumam trabalhar de forma não muito satisfatória e ineficiente com o Hadoop, especialmente ao executar qualquer tarefa MapReduce.
O Apache Pig é um benefício para todos esses programadores.
Usando o Pig Latin, os programadores podem realizar facilmente tarefas MapReduce sem ter que digitar códigos complexos em Java.
Ele usa a abordagem de múltiplas consultas, reduzindo, assim, o tamanho dos códigos.
Por exemplo, uma operação que exige que você digite 200 linhas de código em Java pode ser feita facilmente digitando menos de 10 no Apache Pig.
Por fim, o Apache Pig reduz o tempo de desenvolvimento em quase 16 vezes.
O Pig Latin é uma linguagem semelhante a SQL, portanto, é fácil aprender pra quem tá familiarizado com o SQL.
O Pig fornece muitos operadores integrados para suportar operações de dados como joins, filters, ordering, etc.
Além disso, também fornece tipos de dados aninhados, como tuples, bags e maps que estão ausentes no MapReduce.
Veremos os modelos de dados do Pig na próxima aula.
Executando o Pig
Você pode executar o Pig (executar instruções Pig Latin e comandos Pig) usando vários modos.
Ele tem seis modos de execução ou exectypes:
Local Mode (ótimo para o desenvolvimento) – todos os scripts são executados em uma única máquina sem exigir o Hadoop MapReduce e o HDFS, é muito útil para desenvolver e testar a lógica do Pig. Se você estiver usando um pequeno conjunto de dados para desenvolver ou testar seu código, o modo local poderá ser mais rápido do que passar pela infraestrutura do MapReduce, portanto, para executar o Pig no modo local, você precisa ter acesso a uma única máquina, todos os arquivos são instalados e executados usando seu host local e sistema de arquivos. Especifique o modo local usando o sinalizador -x (pig -x local).
Tez Local Mode – para executar o Pig no Tez Local Mode, é semelhante ao Local Mode, exceto internamente, pois o Pig invocará o mecanismo de tempo de execução tez. Especifique o modo local Tez usando o sinalizador -x (pig -x tez_local).
Nota: O modo local Tez é experimental, existem algumas consultas que podem causar erros ao lidar com grandes quantidades de dados no modo local.
Mapreduce Mode (também conhecido como modo Hadoop) – o Pig é executado no cluster Hadoop. Neste caso, o script Pig é convertido em uma série de tarefas MapReduce que são então executadas no cluster Hadoop, portanto, para executar o Pig no modo MapReduce, você precisa acessar um cluster Hadoop e a instalação do HDFS. O modo MapReduce é o modo padrão, você pode, mas não precisa, especificá-lo usando o sinalizador -x (pig ou pig -x mapreduce).
Tez Mode – para executar o Pig no modo Tez, você precisa acessar um cluster Hadoop e a instalação do HDFS. Especifique o modo Tez usando o sinalizador -x (-x tez).
Spark Mode – Para executar o Pig no modo Spark, você precisa acessar um cluster Spark, Yarn ou Mesos e a instalação do HDFS. Especifique o modo Spark usando o sinalizador -x (-x spark). No modo de execução do Spark, é necessário configurar env :: SPARK_MASTER para um valor apropriado (local – local mode, yarn-client – yarn-client mode, mesos://host:port – spark on mesos or spark://host:port – spark cluster).
O YARN e o Mesos são gerenciadores de contêineres distribuídos.
O YARN é especialmente projetado para cargas de trabalho do Hadoop, enquanto o Mesos é projetado para todos os tipos de cargas de trabalho.
Já o Spark é uma ferramenta de processamento de dados.
O Spark pode rodar no Yarn, da mesma forma que o Hadoop Map Reduce pode rodar também no Yarn.
O Hadoop Map Reduce é um recurso que acompanha o Yarn, o Spark não.
Com o Yarn, por exemplo, digamos que você tenha 4 máquinas, cada uma com 4 GB de RAM e CPUs dual core.
Você pode apresentar o YARN a um aplicativo capaz de distribuir e paralelizar cargas de trabalho, como MapReduce, e o YARN responderá que é possível aceitar 16 GB de carga de trabalho do aplicativo em 8 núcleos de CPU.
Os scripts Pig executados no Spark podem aproveitar o recurso de alocação dinâmica.
O recurso pode ser ativado simplesmente habilitando spark.dynamicAllocation.enabled.
Em geral, todas as propriedades do script pig prefixado com spark, são copiados para a configuração do aplicativo Spark.
Veja que o serviço auxilar Yarn precisa ser ativado no Spark para que isso funcione.
Exemplos
Este exemplo mostra como executar o Pig no modo local e mapreduce usando o comando pig.
/* local mode */
pig -x local ...
/* Tez local mode */
pig -x tez_local ...
/* Spark local mode */
pig -x spark_local ...
/* mapreduce mode */
pig ...
-- ou
pig -x mapreduce ...
/* Tez mode */
$ pig -x tez ...
/* Spark mode */
$ pig -x spark ...
Vamos a um exemplo prático de execução de um script Pig.
Crie um arquivo de texto com o conteúdo abaixo na sua máquina, depois coloque ele na máquina virtual da cloudera através do winscp em uma pasta a sua escolha, no meu caso, eu coloquei no sistema de arquivo local da máquina virtual cloudera em:
/toti/textos/01_exemplo_pig.txt
Paulo Muniz 11995267847 Sao Paulo Engenheiro Ricardo Lima 21986372663 Rio de Janeiro Palestrante Carlos Marques 31993728746 Belo Horizonte Investidor Claudia Duarte 51998274923 Porto Alegre Engenheira Maria Andrade 71986320865 Salvador Professora
Para que o script Pig use esse arquivo, vamos copiar ele para o HDFS, no meu caso para a pasta /user/toti/textos/.
Use o comando para criar a pasta para colocar o 01_exemplo_pig.txt no HDFS:
/user/toti/textos/ no HDFS
hadoop fs -mkdir -p /user/toti/textosUse o comando:
hadoop fs -put /toti/textos/01_exemplo_pig.txt /user/toti/textos/
Agora vamos criar o script.
Crie um arquivo chamado 01_script.pig na sua máquina local e faça uma cópia dele para a máquina virtual cloudera na pasta de sua escolha, no meu caso eu estou usando a pasta /toti/scripts/pig/, para fazer isso use o winscp.
/toti/scripts/pig/01_script.pig
A = LOAD '/user/toti/textos/01_exemplo_pig.txt' using PigStorage (' ') as (FName: chararray, LName: chararray, MobileNo: chararray, City: chararray, Profession: chararray);
B = FOREACH A generate FName, LName, MobileNo, Profession;
DUMP B;
Agora é só rodar o script:
pig /toti/scripts/pig/01_script.pig
Rodamos o script no mapreduce mode, que é o default, quando não especificamos nada.
Parabéns pela execução do seu primeiro script Apache Pig com sucesso!
Modo Interativo do Pig
Você pode executar o Pig no modo interativo usando o shell Grunt.
Invoque o shell Grunt usando o comando “pig” (como mostrado abaixo) e, em seguida, insira suas instruções Pig Latin e os comandos Pig interativamente na linha de comando.
pig
grunt>Exemplo
Estas instruções Pig Latin extraem todos os IDs de usuário do arquivo /etc/passwd.
Primeiro, copie o arquivo /etc/passwd para o HDFS na pasta que você tá usando, no meu caso /user/toti/textos/ com o comando:
hadoop fs -put /etc/passwd /user/toti/textos/Em seguida, invoque o shell Grunt digitando o comando “pig” (no modo local ou hadoop).
Depois, insira as instruções Pig Latin interativamente no prompt Grunt (certifique-se de incluir o ponto-e-vírgula após cada instrução).
O operador DUMP exibirá os resultados na tela do seu terminal. (O grunt> é o prompt do shell Pig interativo)
grunt> A = load '/user/toti/textos/passwd' using PigStorage(':');
grunt> B = foreach A generate $0 as id;
grunt> dump B;
Para chamar o shell interativo Grunt> em:
Local Mode
$ pig -x local
... - Connecting to ...
grunt>
Tez Local Mode
$ pig -x tez_local
... - Connecting to ...
grunt>
Spark Local Mode
$ pig -x spark_local
... - Connecting to ...
grunt>
Mapreduce Mode
$ pig -x mapreduce
... - Connecting to ...
grunt>
-- ou
$ pig
... - Connecting to ...
grunt>
Tez Mode
$ pig -x tez
... - Connecting to ...
grunt>
Spark Mode
$ pig -x spark
... - Connecting to ...
grunt>
Batch Mode (Script)
Você pode executar Pig no modo batch usando scripts Pig e o comando “pig” (no modo local ou hadoop).
Exemplo
As instruções Pig Latin no script Pig (id.pig) extraem todos os IDs de usuário do arquivo /etc/passwd.
Em seguida, vamos executar o script Pig na linha de comando (usando o modo local).
O operador STORE gravará os resultados em um arquivo (toti/textos/id.out).
/* id.pig */
A = load 'etc/passwd' using PigStorage(':'); -- carrega o arquivo passwd
B = foreach A generate $0 as id; -- extrai os IDs dos usuários
store B into 'toti/textos/id.out'; -- escreve os resultados no arquivo id.out
Local Mode
$ pig -x local toti/scripts/pig/id.pig
Tez Local Mode
$ pig -x tez_local id.pig
Spark Local Mode
$ pig -x spark_local id.pig
Mapreduce Mode
$ pig id.pig
-- ou
$ pig -x mapreduce id.pig
Pig Scripts
Use scripts Pig para colocar instruções Pig Latin e comandos Pig em um único arquivo.
Embora não seja obrigatório, é recomendável identificar o arquivo usando a extensão *.pig.
Você pode executar scripts Pig a partir da linha de comando e do shell Grunt (veja os comandos run e exec).
Scripts Pig permitem que você passe valores para parâmetros usando a substituição de parâmetros.
Comentários em Scripts
Você pode incluir comentários nos scripts do Pig:
Para comentários de várias linhas, use / *…. * /
Para comentários de linha única use – –
/* myscript.pig
Meu script é simples. Inclui três comandos Pig Latin.
*/
A = LOAD 'student' USING PigStorage() AS (name:chararray, age:int, gpa:float); -- carrega os dados
B = FOREACH A GENERATE name; -- transforma os dados
DUMP B; -- recupera os resultados
Scripts e sistemas de arquivos distribuídos
Pig suporta a execução de scripts (e arquivos Jar) que são armazenados no HDFS, Amazon S3 e outros sistemas de arquivos distribuídos.
O URI do local completo do script é necessário.
Por exemplo, para executar um script Pig no HDFS, faça o seguinte:
$ pig hdfs://nn.mydomain.com:9020/myscripts/script.pig