
Aula 17 – Scikit-Learn – Reconhecimento facial – Avaliação quantitativa
Aula 17 – Scikit-Learn – Reconhecimento facial – Avaliação quantitativa
Voltar para página principal do blog
Todas as aulas desse curso
Aula 16 Aula 18
Script dessa aula:
Download do script da aula
Documentação oficial do Sklearn:
https://scikit-learn.org/stable/

Reconhecimento facial – Avaliação qualitativa do modelo
Se gostarem do conteúdo dêem um joinha 👍 na página do Código Fluente no
Facebook
Link do código fluente no Pinterest
Meus links de afiliados:
Hostinger
Digital Ocean
One.com
Essa aula é baseada no trabalho apresentado no:
Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments Gary B. Huang,Manu Ramesh, Tamara Berg, and Erik Learned-Miller
Para o download da base LFW é só clicar nesse link abaixo:
https://scikit-learn.org/stable/auto_examples/applications/plot_face_recognition.html
Ou da fonte original
http://vis-www.cs.umass.edu/lfw/
Avaliação quantitativa do modelo
Agora que temos o modelo criado, precisamos avaliá-lo, saber se realmente ele funcionará e será útil.
Contextualizando o modelo
Coisas que talvez você já saiba, mas, acho que vale a pena reforçar.
Os cinco tipos de problema em que o aprendizado de máquina é em geral aplicado ao invés da programação convencional, são:
- Classificador (Ex. Esse email é span, ou não? Esse produto é bom ou ruim? Essa figura é uma face ou não?)
- Regressor (Ex. Qual o valor de? Qual a quantidade de? Qual será a cotação de? …)
- Detecção de anomalia (Ex. Essa movimentação bancária é fraudulenta? Esse usuário costuma fazer compras internacionais?…)
- Organização de distribuição (Ex. Agrupar usuários que preferem filmes românticos, ou que que gostem de turismo ecológico…)
- Prevenção (Ex. O que vai acontecer depois? Qual o próximo passo? Quais máquinas precisam de manutenção preventiva?…)
O modelo do nosso exemplo se enquadra no primeiro caso, um classificador.
Estamos na fase de avaliação quantitativa dele.
Existem dois tipos de inteligência artificial:
- Forte não é uma inteligência específica.
- Fraca é uma inteligência específica.
E dentro da inteligência artificial, dois tipos básicos de aprendizado de máquina:
- supervisionado
- não supervisionado
O modelo do nosso exemplo é uma inteligência artificial fraca, ele é específico para reconhecer faces.
Foi criado de forma supervisionada, ou seja, ele aprendeu com os dados disponíveis para o treinamento.
Agora sim, vamos seguir! 😉
Na etapa em que estamos, vamos usar a parte dos dados que separamos para os testes, para fazer a avaliação quantitativa do modelo classificador que criamos.
Código completo
"""
================================
Faces recognition example using eigenfaces and SVMs
================================
An example showing how the scikit-learn can be used to faces recognition with eigenfaces and SVMs
================================
================================
================================
Exemplo de reconhecimento de faces usando autofaces e SVMs
================================
Exemplo mostrando como o scikit-learn pode ser usado para reconhecimento de faces com autofaces e SVMs
"""
from time import time
import logging
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.datasets import fetch_lfw_people
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.decomposition import PCA
from sklearn.svm import SVC
print(__doc__)
# O logging exibe o progresso da execução no stdout
# adicionando as informações de data e hora
logging.basicConfig(level=logging.INFO, format='%(asctime)s %(message)s')
# #############################################################################
# Download dos dados, se ainda não estiver em disco e carregue-a como uma matriz numpy
lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)
# Inspeciona as matrizes de imagens para encontrar os formatos das imagens( para plotagem )
n_samples, h, w = lfw_people.images.shape
# para aprendizado de máquina, usamos 2 dados diretamente( esse modelo ignora
# informações relativas a posição do pixel )
X = lfw_people.data
n_features = X.shape[1]
# A rótulo( label ) a prever é o ID da pessoa
y = lfw_people.target
target_names = lfw_people.target_names
n_classes = target_names.shape[0]
print("Total dataset size:")
print(f"n_samples: {n_samples}")
print(f"n_features: {n_features}")
print(f"n_classes: {n_classes}")
# #############################################################################
# Divide a base em um conjunto de treinamento e um conjunto de teste usando k fold
# 25% da base para o conjunto de teste os 75% restantes para o treino
# random_state é para inicializar o gerador interno de números aleatórios
# Definir random_state com um valor fixo garantirá que a mesma sequência de números
# aleatórios seja gerada cada vez que você executar o código
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42)
# #############################################################################
# Computa o principal component analysis - PCA (eigenfaces) na base de faces
# ( tratado como dataset não rotulado ): extração não supervisionada / redução de dimensionalidade
n_components = 150
print(f"Extracting the top {n_components} eigenfaces from {X_train.shape[0]} faces")
# t0 guarda o tempo zero, para cálculo do tempo de execução do PCA
# O cálculo é feito no time() - t0 do print da linha 81
t0 = time()
pca = PCA(n_components=n_components, svd_solver='randomized',
whiten=True).fit(X_train)
print("done in {0:.3f}s".format(time() - t0))
eigenfaces = pca.components_.reshape((n_components, h, w))
print("Projecting the input data on the eigenfaces orthonormal basis")
t0 = time()
X_train_pca = pca.transform(X_train)
X_test_pca = pca.transform(X_test)
print("done in {0:.3f}s".format(time() - t0))
# #############################################################################
# Treinando um modelo de classificação SVM
print("Fitting the classifier to the training set")
t0 = time()
param_grid = {'C': [1e3, 5e3, 1e4, 5e4, 1e5],
'gamma': [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.1], }
clf = GridSearchCV(SVC(kernel='rbf', class_weight='balanced'), param_grid)
clf = clf.fit(X_train_pca, y_train)
print("done in {0:.3f}s".format(time() - t0))
print("Best estimator found by grid search:")
print(clf.best_estimator_)
# #############################################################################
# Avaliação quantitativa da qualidade do modelo sobre o conjunto de testes
print("Predicting people's names on the test set")
t0 = time()
y_pred = clf.predict(X_test_pca)
print("done in {0:.3f}s".format(time() - t0))
print(classification_report(y_test, y_pred, target_names=target_names))
print(confusion_matrix(y_test, y_pred, labels=range(n_classes)))
# #############################################################################
# Avaliação qualitativa das previsões usando matplotlib
def plot_gallery(images, titles, h, w, n_row=3, n_col=4):
"""Helper function to plot a gallery of portraits"""
plt.figure(figsize=(1.8 * n_col, 2.4 * n_row))
plt.subplots_adjust(bottom=0, left=.01, right=.99, top=.90, hspace=.35)
for i in range(n_row * n_col):
plt.subplot(n_row, n_col, i + 1)
plt.imshow(images[i].reshape((h, w)), cmap=plt.cm.gray)
plt.title(titles[i], size=12)
plt.xticks(())
plt.yticks(())
# Plota o resultado da previsão em uma parte do conjunto de testes
def title(y_pred, y_test, target_names, i):
pred_name = target_names[y_pred[i]].rsplit(' ', 1)[-1]
true_name = target_names[y_test[i]].rsplit(' ', 1)[-1]
return f'predicted: {pred_name}\ntrue: {true_name}'
prediction_titles = [title(y_pred, y_test, target_names, i)
for i in range(y_pred.shape[0])]
plot_gallery(X_test, prediction_titles, h, w)
# plota a galeria das autofaces mais significativas
eigenface_titles = [f"eigenface {i}" for i in range(eigenfaces.shape[0])]
plot_gallery(eigenfaces, eigenface_titles, h, w)
# inicia um loop de eventos, procura todos os objetos de figura ativos
# no momento e abre uma ou mais janelas interativas que exibem sua figura
# ou figuras
plt.show()
Avaliação quantitativa da qualidade do modelo
Nossas classes alvo são:
[‘Ariel Sharon’, ‘Colin Powel’, ‘Donald Rumsfeld’, ‘George W Bush’, ‘Gerhard Schroeder’, ‘Hugo Chavez’, ‘Tony Blair’]
Esses dados estão guardados em lfw_people.target_names, ou seja, na chave target_names do dicionário que é a base lfw_people.
Nessa parte do código, o modelo clf criado no passo anterior, irá prever os nomes dessas pessoas no conjunto de teste.
Linha:
y_pred = cls.predict(X_test_pca)
Relatório de classificação
A função classification_report cria um relatório de texto mostrando as principais métricas de classificação.
Linha:
print(classification_report(y_test, y_pred, target_names=target_names))
A saída é a seguinte:
precision recall f1-score support
Ariel Sharon 0.75 0.46 0.57 13
Colin Powell 0.80 0.87 0.83 60
Donald Rumsfeld 0.90 0.67 0.77 27
George W Bush 0.83 0.98 0.90 146
Gerhard Schroeder 0.95 0.80 0.87 25
Hugo Chavez 1.00 0.53 0.70 15
Tony Blair 0.96 0.75 0.84 36
accuracy 0.85 322
macro avg 0.89 0.72 0.78 322
weighted avg 0.86 0.85 0.84 322
Matriz de confusão
Linha:
print(confusion_matrix(y_test, y_pred, labels=range(n_classes)))
A saída é a seguinte:
[[ 6 2 0 5 0 0 0]
[ 1 52 1 6 0 0 0]
[ 1 2 18 6 0 0 0]
[ 0 3 0 143 0 0 0]
[ 0 1 0 3 20 0 1]
[ 0 3 0 3 1 8 0]
[ 0 2 1 6 0 0 27]]
Exemplo 2D
Vamos a um exemplo simples para ficar melhor de entender:
y_true são os valores, onde cada posição do array booleano representa uma mulher grávida ou não.
y_pred são os valores que o modelo previu para cada mulher no conjunto de teste, acertando uns e errando outros.
from sklearn.metrics import classification_report, confusion_matrix
y_true = [False, True, False, True, False, False, False, False, True, False]
y_pred = [False, True, True, False, False, False, False, True, True, True]
target_names = ['Não grávidas', 'Grávidas']
print(classification_report(y_true, y_pred, target_names=target_names))
print(confusion_matrix(y_true, y_pred))
Saída:
precision recall f1-score support
Não grávidas 0.80 0.57 0.67 7
Grávidas 0.40 0.67 0.50 3
accuracy 0.60 10
macro avg 0.60 0.62 0.58 10
weighted avg 0.68 0.60 0.62 10
Matriz de confusão
[[4 3] [1 2]]

Matriz de confusão

Entendendo alguns conceitos
Positivos verdadeiros(True Positive): Indica a quantidade de registros que foram classificados como positivos corretamente, isto é, a resposta do classificador foi “Grávida” e realmente, aquela determinada paciente estava.
Negativos verdadeiros(True Negative): Indica a quantidade de registros que foram classificados como negativo de maneira correta, ou seja, a resposta do classificador foi “Não Grávida” e a paciente em questão realmente não estava grávida.
Falsos positivos(False Positive): Indica a quantidade de registros que foram classificados como “Grávida” de maneira incorreta, ou seja, a resposta do classificador foi que determinada paciente estava grávida, quando não estava.
Falsos negativos(False Negative): Indica a quantidade de registros que foram classificados como “Não Grávida” de maneira incorreta, ou seja, a resposta do classificador foi negativo para gravidez(“Não Grávida“), mas, a resposta correta seria “Grávida“.
Através desses quatro valores, poderemos calcular os indicadores: Accuracy, Precision, Recall e F1 Score.
Accuracy
Precisamos ter um certo cuidado com essa métrica, por exemplo, digamos que nosso modelo responda sempre: “Não Grávida“.
Vamos supor que nossa base de dados será composta por 90% de registros de mulheres que não estão grávidas e 10% sim.
Nosso modelo teria uma acurácia de 90% mesmo sendo totalmente tosco.
É importante que tenhamos uma distribuição o mais uniforme possível das classes alvo na base de dados para que a accuracy não fique tendenciosa.
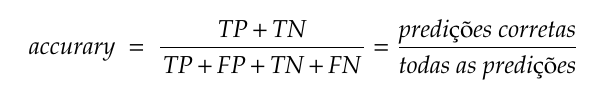
Fórmula da acurácia
Precision
É utilizado para indicar a relação entre as previsões positivas realizadas corretamente e todas as previsões positivas(incluindo as falsas).
Para o nosso modelo ela seria utilizada para responder a seguinte questão:
De todos os registros classificados como “Grávida“, qual percentual realmente foi positivo?
Qual a proporção de identificações positivas para gravidez foi realmente correta?
Em outras palavras, o quão bem o modelo se saiu?
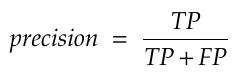
Fórmula da precisão
Recall
O recall pode ser usado em casos que os Falsos Negativos podem ser mais prejudiciais que os Falsos Positivos.
Exemplo, o modelo deve encontrar todos os pacientes doentes, mesmo que classifique alguns saudáveis como doentes (situação de Falso Positivo).
Ou seja, o modelo deve ter alto recall, porque classificar pacientes doentes como saudáveis pode ser uma tragédia.
O recall pode responder a seguinte pergunta: qual a proporção de positivos foi identificado corretamente?
Em outras palavras, quão bom o modelo é para prever positivos, sendo positivo entendido como a classe que se quer prever, no nosso contexto, se a paciente está grávida.
É definido como razão entre verdadeiros positivos e a soma de verdadeiros positivos somados aos falsos negativos.
F1-Score
O F1-score nos mostra a relação entre a precisão e o recall do modelo.
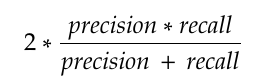
F1-score
O F1-score é uma maneira de se observar somente uma métrica ao invés de duas(precisão e recall)
É uma média harmônica entre as duas, que está muito mais próxima dos menores valores do que uma média aritmética simples.
Isto é, quando se tem um F1-score baixo, é porque ou a precisão, ou o recall está baixo.
Ficamos por aqui e na próxima aula vamos ver a parte da avaliação qualitativa do modelo.
https://scikit-learn.org/stable/auto_examples/applications/plot_face_recognition.html
Voltar para página principal do blog
Todas as aulas desse curso
Aula 16 Aula 18
Link do meu Github com o script dessa aula:
Download do script da aula
Se gostarem do conteúdo dêem um joinha 👍 na página do Código Fluente no
Facebook
Link do código fluente no Pinterest
Novamente deixo meus link de afiliados:
Hostinger
Digital Ocean
One.com
Obrigado, até a próxima e bons estudos. 😉





O link do Script do Git hub está trocado para algumas aulas.
Vlw Flávio, obrigado por avisar.
Corrigido.
\o/