Aula 18 – Scikit-Learn – Reconhecimento facial – Avaliação qualitativa
Aula 18 – Scikit-Learn – Reconhecimento facial – Avaliação qualitativa
Voltar para página principal do blog
Todas as aulas desse curso
Aula 17 Aula 19
Script dessa aula:
Download do script da aula
Documentação oficial do Sklearn:
https://scikit-learn.org/stable/

Reconhecimento facial – Avaliação qualitativa do modelo
Se gostarem do conteúdo dêem um joinha 👍 na página do Código Fluente no
Facebook
Link do código fluente no Pinterest
Meus links de afiliados:
Hostinger
Digital Ocean
One.com
Essa aula é baseada no trabalho apresentado no:
Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments Gary B. Huang,Manu Ramesh, Tamara Berg, and Erik Learned-Miller
Para o download da base LFW é só clicar nesse link abaixo:
https://scikit-learn.org/stable/auto_examples/applications/plot_face_recognition.html
Ou da fonte original
http://vis-www.cs.umass.edu/lfw/
Avaliação qualitativa do classificador
Antes, vamos lembrar o que fizemos na aula passada.
Avaliação Quantitativa do Modelo
Os dois métodos quantitativos mais utilizados para análise de dados são estatística descritiva e estatística inferencial.
A estatística descritiva (também conhecida como análise descritiva) geralmente é o primeiro nível da análise.
Isso ajuda os pesquisadores a resumir os dados e encontrar padrões.
Algumas estatísticas descritivas usadas com frequência são:
- Média : média numérica de um conjunto de valores.
- Mediana : ponto médio de um conjunto de valores numéricos.
- Moda : valor mais comum entre um conjunto de valores.
- Porcentagem : proporção de uma quantidade ou grandeza em relação a uma outra avaliada sobre a centena.
- Frequência : o número de vezes que um valor é encontrado.
- Intervalo : o valor mais alto e mais baixo em um conjunto de valores.
Foi o que fizemos na aula passada.
Análise qualitativa
Nessa aula trataremos a parte do código referente a análise qualitativa do classificador criado, a parte em laranja no código abaixo.
Métodos Qualitativos de Análise de Dados
Vários métodos estão disponíveis para analise de dados qualitativos.
Os métodos mais usados são:
- Análise de conteúdo: este é um dos métodos mais comuns para analisar dados qualitativos, é usado para analisar informações documentadas na forma de textos, mídia ou mesmo itens físicos.
- Análise narrativa: esse método é usado para analisar o conteúdo de várias fontes, dados textuais garimpados de variadas maneiras: pesquisas, crawlers, etc.
- Análise do discurso: a análise do discurso ou narrativa, é usada para analisar as interações com as pessoas, no entanto, concentra-se em analisar o contexto social em que ocorreu a comunicação.
- Teoria fundamentada: refere-se ao uso de dados qualitativos para explicar por que um determinado fenômeno aconteceu, isso é feito estudando uma variedade de casos semelhantes em diferentes configurações e usando os dados para derivar explicações da causa.
No caso aqui do exemplo da classificação das faces, usaremos o matplotlib para previsões da qualidade do modelo, plotando algumas imagens das faces, mostrando o valor correto e o valor previsto para as faces alvo.
Mostrando também algumas eingefaces.
Na verdade, são mostradas apenas 12 imagens, já que plot_gallery() foi definida dessa forma:
plot_gallery(images, titles, h, w, n_row=3, n_col=4)
Então, 3 X 4 = 12, serão plotadas 12 imagens apenas .
Façam o teste trocando esses números.
Código completo
"""
================================
Faces recognition example using eigenfaces and SVMs
================================
An example showing how the scikit-learn can be used to faces recognition with eigenfaces and SVMs
================================
================================
================================
Exemplo de reconhecimento de faces usando autofaces e SVMs
================================
Exemplo mostrando como o scikit-learn pode ser usado para reconhecimento de faces com autofaces e SVMs
"""
from time import time
import logging
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.datasets import fetch_lfw_people
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.decomposition import PCA
from sklearn.svm import SVC
print(__doc__)
# O logging exibe o progresso da execução no stdout
# adicionando as informações de data e hora
logging.basicConfig(level=logging.INFO, format='%(asctime)s %(message)s')
# #############################################################################
# Download dos dados, se ainda não estiver em disco e carregue-a como uma matriz numpy
lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)
# Inspeciona as matrizes de imagens para encontrar os formatos das imagens( para plotagem )
n_samples, h, w = lfw_people.images.shape
# para aprendizado de máquina, usamos 2 dados diretamente( esse modelo ignora
# informações relativas a posição do pixel )
X = lfw_people.data
n_features = X.shape[1]
# A rótulo( label ) a prever é o ID da pessoa
y = lfw_people.target
target_names = lfw_people.target_names
n_classes = target_names.shape[0]
print("Total dataset size:")
print(f"n_samples: {n_samples}")
print(f"n_features: {n_features}")
print(f"n_classes: {n_classes}")
# #############################################################################
# Divide a base em um conjunto de treinamento e um conjunto de teste usando k fold
# 25% da base para o conjunto de teste os 75% restantes para o treino
# random_state é para inicializar o gerador interno de números aleatórios
# Definir random_state com um valor fixo garantirá que a mesma sequência de números
# aleatórios seja gerada cada vez que você executar o código
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42)
# #############################################################################
# Computa o principal component analysis - PCA (eigenfaces) na base de faces
# ( tratado como dataset não rotulado ): extração não supervisionada / redução de dimensionalidade
n_components = 150
print(f"Extracting the top {n_components} eigenfaces from {X_train.shape[0]} faces")
# t0 guarda o tempo zero, para cálculo do tempo de execução do PCA
# O cálculo é feito no time() - t0 do print da linha 81
t0 = time()
pca = PCA(n_components=n_components, svd_solver='randomized',
whiten=True).fit(X_train)
print("done in {0:.3f}s".format(time() - t0))
eigenfaces = pca.components_.reshape((n_components, h, w))
print("Projecting the input data on the eigenfaces orthonormal basis")
t0 = time()
X_train_pca = pca.transform(X_train)
X_test_pca = pca.transform(X_test)
print("done in {0:.3f}s".format(time() - t0))
# #############################################################################
# Treinando um modelo de classificação SVM
print("Fitting the classifier to the training set")
t0 = time()
param_grid = {'C': [1e3, 5e3, 1e4, 5e4, 1e5],
'gamma': [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.1], }
clf = GridSearchCV(SVC(kernel='rbf', class_weight='balanced'), param_grid)
clf = clf.fit(X_train_pca, y_train)
print("done in {0:.3f}s".format(time() - t0))
print("Best estimator found by grid search:")
print(clf.best_estimator_)
# #############################################################################
# Avaliação quantitativa da qualidade do modelo sobre o conjunto de testes
print("Predicting people's names on the test set")
t0 = time()
y_pred = clf.predict(X_test_pca)
print("done in {0:.3f}s".format(time() - t0))
print(classification_report(y_test, y_pred, target_names=target_names))
print(confusion_matrix(y_test, y_pred, labels=range(n_classes)))
# #############################################################################
# Avaliação qualitativa das previsões usando matplotlib
def plot_gallery(images, titles, h, w, n_row=3, n_col=4):
"""Helper function to plot a gallery of portraits"""
plt.figure(figsize=(1.8 * n_col, 2.4 * n_row))
plt.subplots_adjust(bottom=0, left=.01, right=.99, top=.90, hspace=.35)
for i in range(n_row * n_col):
plt.subplot(n_row, n_col, i + 1)
plt.imshow(images[i].reshape((h, w)), cmap=plt.cm.gray)
plt.title(titles[i], size=12)
plt.xticks(())
plt.yticks(())
# Plota o resultado da previsão em uma parte do conjunto de testes
def title(y_pred, y_test, target_names, i):
pred_name = target_names[y_pred[i]].rsplit(' ', 1)[-1]
true_name = target_names[y_test[i]].rsplit(' ', 1)[-1]
return f'predicted: {pred_name}\ntrue: {true_name}'
prediction_titles = [title(y_pred, y_test, target_names, i)
for i in range(y_pred.shape[0])]
plot_gallery(X_test, prediction_titles, h, w)
# plota a galeria das autofaces mais significativas
eigenface_titles = [f"eigenface {i}" for i in range(eigenfaces.shape[0])]
plot_gallery(eigenfaces, eigenface_titles, h, w)
# inicia um loop de eventos, procura todos os objetos de figura ativos
# no momento e abre uma ou mais janelas interativas que exibem sua figura
# ou figuras
plt.show()
Analisando a parte em laranja do código
Função plot_gallery()
A função plot_gallery recebe as imagens do conjunto de teste, já com PCA, os títulos previstos, a altura e a largura e define que as imagens serão mostradas em 3 linhas e 4 colunas.

Imagens plotadas pela plot_gallery
Depois temos plt.figure e plt.subplots_adjust com alguns parâmetros.
Os parâmetros do plt.figure são para ajuste do tamanho das fotos na plotagem.
E os parâmetros do plt.subplots_adjust definem o espaçamento entre as fotos.
Com o plt.figure criamos uma instância de uma foto usando matplotlib.pyplot.figure (), que é um método conveniente para instanciar Figuras e conectá-las à interface do usuário ou ao FigureCanvas do kit de ferramentas de desenho.
Em seguida temos um loop for no range de número de linhas(3) vezes o número de colunas(4), ou seja, no range(12).
Dentro do loop for da plot_gallery()
Subplot
Em plt.subplot(n_row, n_col, i + 1), os parâmetros indicam o número total de linhas, colunas e o terceiro parâmetro é o índice da figura.
O index começa em 1 no canto superior esquerdo e aumenta para a direita.
O primeiro subplot é a primeira coluna da primeira linha, o segundo subplot é a segunda coluna da primeira linha e assim por diante.
O index começa em 1, por isso o i + 1 em plt.subplot(n_row, n_col, i + 1).
Usando com i apenas, vai dá o seguinte erro:
ValueError: num must be 1 <= num <= 12, not 0
imshow
A função matplotlib imshow() cria uma imagem a partir de uma matriz numpy bidimensional.
A imagem terá um quadrado para cada elemento da matriz.
A cor de cada quadrado é determinada pelo valor do elemento da matriz correspondente e pelo mapa de cores usado por imshow(), no caso do nosso exemplo, o mapa plt.cm.gray.
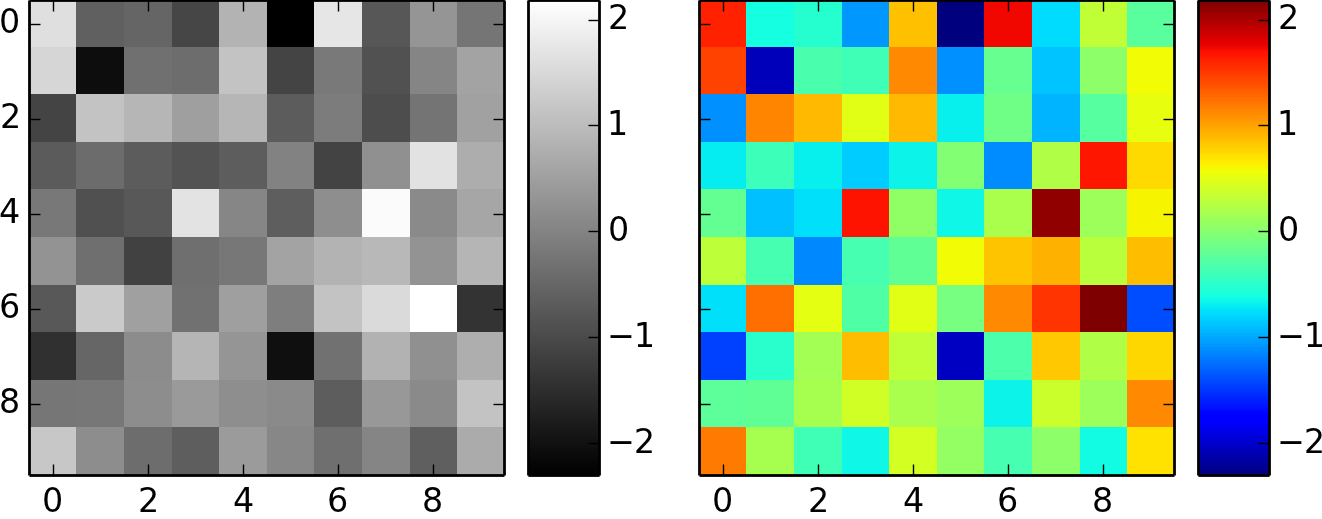
cmap
O cmap vai mapear os valores numéricos para cada quadrado (pixel) correspondente, referentes as intensidades das cores vermelho, verde e azul entre 0 e 1, se for imagem colorida , ou intensidade de cinza se for preto e branco.
Quando uma imagem tem forma (M,N,3)ou (M,N,4), os valores são interpretados como valores RGB ou RGBA.
Nesse caso, o cmap é ignorado.
No exemplo que estamos trabalhando das imagens de faces, o formato das imagens é uma matriz M X N.
Vamos pegar uma imagem qualquer, a da posição 2 no conjunto de teste pra ver a matriz.
X_test[2].reshape((h, w))
Saída:
array([[ 70. , 111.333336, 128.33333 , …, 130.33333 , 117.666664,
91.666664],
[ 76. , 117.666664, 125.333336, …, 138.66667 , 138.66667 ,
118.666664],
[ 93.666664, 118. , 119. , …, 142. , 150.66667 ,
140.33333 ],
…,
[ 38.333332, 42. , 37. , …, 128.66667 , 168. ,
181.33333 ],
[ 38. , 40. , 37. , …, 145.66667 , 184.66667 ,
175. ],
[ 39.333332, 37.333332, 35. , …, 172.66667 , 185.33333 ,
172. ]], dtype=float32)
Vamos plotar a imagem 2?
plt.imshow(X_test[2].reshape((h, w)), cmap=plt.cm.gray)
plt.show()
Faça testes trocando o índice da foto.
Enfim, voltando, no caso do exemplo que estamos vendo, como temos uma matriz de forma (M,N), o cmap é quem controla o mapa de cores usado para exibir as imagens.
title
A plt.title() define um título para os eixos.
Ela tem um parâmetro plt.title(titles[i], size=12), que se refere ao tamanho da fonte do título.
ticks
xticks() # Obtém as localizações e as etiquetas(labels) do eixo X.
yticks() # Obtém as localizações e as etiquetas(labels) do eixo Y.
Com isso encerramos a análise da função plot_gallery()
Função title()
A linha pred_name = target_names[y_pred[i]].rsplit(‘ ‘, 1)[-1] pega os nomes que o modelo previu.
Já em true_name = target_names[y_test[i]].rsplit(‘ ‘, 1)[-1] pega os nomes corretos.
Para entender melhor as linhas acima, imagine que:
target_names[y_pred[i]] = ‘George W Bush’
Definir o parâmetro maxsplit como 1 no .rsplit(‘ ‘, 1), retornará uma lista com 2 elementos [‘George W’, ‘Bush’].
O primeiro elemento é a string ‘George W’ e o segundo ‘Bush’.
E o [ -1] do .rsplit(‘ ‘, 1)[-1], pega só o último elemento, nesse caso, só o ‘Bush’.
No final a função retorna f’predicted: {pred_name}\ntrue: {true_name}’
Ou seja, uma lista tipo: [‘predicted: Bush\ntrue: Bush’, ‘predicted: Bush\ntrue: Bush’, ‘predicted: Blair\ntrue: Blair’, ‘predicted: Bush\ntrue: Bush’, ‘predicted: Bush\ntrue: Bush’, ‘predicted: Bush\ntrue: Bush’, ‘predicted: Schroeder\ntrue: Schroeder’, ‘predicted: Powell\ntrue: Powell’, ‘predicted: Bush\ntrue: Bush’, ‘predicted: Bush\ntrue: Bush’, ‘predicted: Bush\ntrue: Bush’, ‘predicted: Bush\ntrue: Bush’, ‘predicted: Bush\ntrue: Bush’, ‘predicted: Bush\ntrue: Blair’, ‘predicted: Bush\ntrue: Bush’, ‘predicted: Bush\ntrue: Bush’, ‘predicted: Bush\ntrue: Bush’, ‘predicted: Bush\ntrue: Bush’, ‘predicted: Bush\ntrue: Bush’, ‘predicted: Schroeder\ntrue: Schroeder’, ‘predicted: Powell\ntrue: Powell’…]
Aqui encerramos a análise da title()
Chamadas da title()
Agora temos a linha:
prediction_titles = [title(y_pred, y_test, target_names, i) for i in range(y_pred.shape[0])]
Foi usado List Comprehension, para preencher o prediction_title.
O target_names são nossas classes alvo:
[‘Ariel Sharon’, ‘Colin Powell’, ‘Donald Rumsfeld’, ‘George W Bush’,’Gerhard Schroeder’, ‘Hugo Chavez’, ‘Tony Blair’]
O y_pred são os valores que o modelo previu na hora que fizemos a avaliação quantitativa.
O y_test são os valores corretos para que possamos avaliar nosso classificador e saber se ele tá acertando, ou o quanto ele tá acertando e o quanto tá errando.
Primeira chamada da plot_gallery()
Em seguida temos a primeira chamada da nossa plot_gallery(X_test, prediction_titles, h, w).
Para ela será passado o X_test, que é a parte da base em que o classificador não foi treinado, portanto, o classificador não conhece esses dados.
O prediction_titles guarda a lista retornada pela função title(), mostrada parcialmente acima em verde.
O h (altura) e o w (largura) foram pegos logo no início do código em:
n_samples, h, w = lfw_people.images.shape
Segunda chamada da plot_gallery()
Antes da segunda chamada temos: eigenface_titles = [f”eigenface {i}” for i in range(eigenfaces.shape[0])]
Essa linha vai colocar em cada imagem: eigenface 0, eigenface 1, eigenface 2 …
Em seguida a segunda chamada da plot_gallery() passando: a eigenfaces (que foi resultado do PCA), eigenface_titles (resultado da linha anterior), a altura(h) e a largura(w).
plt.show()
Por fim, plt.show(), ela inicia um loop de eventos, procura todos os objetos de figura ativos no momento e abre uma ou mais janelas interativas que exibem sua figura ou figuras.
Ficamos por aqui, com essa aula encerramos a explicação do código:
https://scikit-learn.org/stable/auto_examples/applications/plot_face_recognition.html
Voltar para página principal do blog
Todas as aulas desse curso
Aula 16 Aula 18
Link do meu Github com o script dessa aula:
Download do script da aula
Se gostarem do conteúdo dêem um joinha 👍 na página do Código Fluente no
Facebook
Link do código fluente no Pinterest
Novamente deixo meus link de afiliados:
Hostinger
Digital Ocean
One.com
Obrigado, até a próxima e bons estudos. 😉