Aula 18 – Tensor Flow – Redes Neurais – Rede Neural Convolucional
Aula 18 – Tensor Flow – Redes Neurais – Rede Neural Convolucional
Voltar para página principal do blog
Todas as aulas desse curso
Aula 17 Aula 19
Meu github:
https://github.com/toticavalcanti
Documentação oficial do TensorFlow:
https://www.tensorflow.org/
Quer aprender python3 de graça e com certificado? Acesse então:
https://workover.com.br/python-codigo-fluente

Python com Tensorflow
Se gostarem do conteúdo dêem um joinha 👍 na página do Código Fluente no
Facebook
https://digitalinnovation.one/
Link do código fluente no Pinterest
Aproveito para deixar meus link de afiliados:
Hostinger
Digital Ocean
One.com
Toti:
https://www.youtube.com/channel/UCUEtjLuDpcOvR3mIUr-viOA
Backing track / Play-along:
https://www.youtube.com/channel/UCT3TryVMqTqYBjf5g5WAHfA
Código Fluente
https://www.youtube.com/channel/UCgn-O-88XBAwdG9gUWkkb0w
Putz!
https://www.youtube.com/channel/UCZXop2-CECwyFYmHbhnAkAw
Fiquem a vontade para me adicionar ao linkedin.
Aula 18 – Tensor Flow – Redes Neurais – Rede Neural Convolucional
Rede Neural Convolucional (CNN)
Inicialização de pesos
Poderíamos inicializar todos os pesos com zeros.
No entanto teremos um problema de não aleatoriedade, isto é imparcial.
Teremos um problema de não aleatoriedade e como a rede treina com um padrão estocástico, usando a descida de gradiente, é necessário ser imparcial, ser aleatório na inicialização dos pesos.
Estocástico vs. Determinístico
Estocástico é sinônimo de probabilidade, temos uma probabilidade de determinado evento ocorrer em termos de porcentagem.
Já o determinismo não tem erro, 2 + 2 sempre será 4, assim como, se você sabe a posição inicial de um objeto, sabe a velocidade, o tempo e a aceleração, você consegue saber onde estará o objeto depois de certo tempo se passar.
Ou seja, você consegue saber exatamente qual o estado do objeto, já no caso de eventos estocásticos, como o lançamento de um dado, você não consegue determinar esse estado.
Um exemplo que mistura componentes estocásticos e determinísticos são as cotações de ações, de ativos, de moedas em Tempo Real.
Esse tipo de dado tem um componente estocástico, ou seja, imprevisível, e alguns determinísticos também, ou seja, previsíveis, por exemplo, o presidente dos USA faz alguma declaração que pode levar a queda, ou a subida de determinados ativos.
Ou acontece algum desastre natural, algum escândalo envolvendo alguma instituição importante, enfim, várias coisas podem impactar nas cotações de moedas e ativos.
É por isso que investidores conseguem muitas vezes acertar se determinado ativo vai subir ou cair.
E já algum tempo, tem robôs que implementam uma automação de como os investidores agem, baseado em IA usando os dados anteriores, os dados passados sobre os ativos, disparando compras e vendas automaticamente.
Seguindo
Podemos usar uma distribuição aleatória uniforme ou normal indo de -1 a 1, mas também não funciona bem, porque pode acontecer dessas distribuições aleatórias distorcerem para valores muito maiores quando passadas para a função de ativação.
Solução
Vamos usar a inicialização de Xavier.
Veja o artigo Compreender a dificuldade de treinar redes neurais profundas de feedforward
de Xavier Glorot, Yoshua Bengio mostrado na Décima Terceira Conferência Internacional sobre Inteligência Artificial e Estatística, PMLR 9: 249-256, 2010.
Eles afirmam que antes de 2006, parece que as redes neurais multicamadas profundas não foram treinadas com sucesso.
Desde então vários algoritmos foram usados para treiná-las com sucesso, com resultados experimentais mostrando a superioridade de arquiteturas mais profundas em relação as menos.
Todos os resultados experimentais foram obtidos com novos mecanismos de inicialização ou treinamento.
O objetivo era entender melhor o porquê da descida de gradiente padrão da inicialização aleatória estava indo tão mal com redes neurais profundas, para ajudar a projetar algoritmos melhores no futuro.
Sigmóide não é adequada para redes profundas
Primeiro eles observaram a influência das funções de ativações não lineares.
Descobriram que a função de ativação logística sigmóide não é adequada para redes profundas com inicialização aleatória por causa de seu valor médio, que pode levar especialmente a camada oculta superior à saturação.
Surpreendentemente, descobriram que as unidades saturadas podem sair da saturação por si mesmas, embora lentamente, o que explica os platôs às vezes vistos durante o treinamento de redes neurais.
Descobriram que a não linearidade, que satura menos pode muitas vezes ser benéfica.
Por fim, estudaram como as ativações e gradientes variam entre as camadas e durante o treinamento, com a ideia de que o treinamento pode ser mais difícil quando os valores singulares do Jacobiano associados a cada camada estão distantes de 1.
Com base nessas considerações, eles propuseram uma novo esquema de inicialização que traz uma convergência substancialmente mais rápida.
Inicialização de Xavier
A inicialização do Xavier podem ser distribuições uniformes ou distribuições normais.
A ideia básica da inicialização do Xavier é gerar pesos em uma distribuição que tem média zero e uma variância específica.
Ou a variância é definida como variância de W igual a 1 sobre e N.
var(w) = 1 / n (neurônios de entrada)
Onde w é a distribuição de inicialização para o neurônio em questão e n é o número de neurônios que o alimentam.
Portanto, este é um neurônio específico.
Novamente W é a distribuição de inicialização para aquele neurônio em questão.
O número de neurônios que alimentam esse neurônio específico e a distribuição tipicamente gaussiana ou uniforme.
Gaussiano é apenas outra palavra para se referir a uma distribuição normal.
Suponha que temos uma entrada X com n componentes e um neurônio linear com pesos aleatórios W que produz uma saída Y.
A variância de Y pode ser escrita como:
Y = W1X1 + W2X2 + ⋯ + WnXn
Sabemos que a variação do WiXi é:
Var(WiXi) = E(Xi)^2Var(Wi) + E(Wi)^2Var(Xi) + Var(Wi)Var(Xi)
Aqui, assumimos que Xi e Wi são todos independentes e distribuídos de forma idêntica, em uma distribuição gaussiana com média zero, podemos calcular a variância de Y como:
Var(Y)= Var(W1X1 + W2X2 + ⋯ + WnXn)
= Var(W1X1) + Var(W2X2) + ⋯ + Var(WnXn)
= nVar(Wi)Var(Xi)
A variação da saída é a variação da entrada, mas, é dimensionada por nVar(Wi).
Portanto, se quisermos que a variância de Y seja igual à variância de X, o termo nVar(Wi) deve ser igual a 1.
Então, a variância do peso deve ser:
var(w) = 1 / n = 1 / n (neurônios de entrada)
Originalmente no artigo artigo de Xavier e Bengio é recomendado o uso da fórmula:
var(w) = 2 / n (neurônios de entrada) + n (neurônios de saída)
Ainda existe outra variação da fórmula.
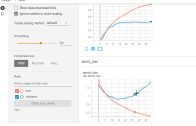
Descida de gradiente
Três componentes do gradiente:
- Taxa de aprendizagem(Learning Rate ) – define o tamanho do passo durante a descida do gradiente.
- Valores Menores → pode levar uma eternidade para treinar o modelo e até mesmo nunca convergir dentro de um prazo razoável.
- Valores Maiores → pode ultrapassar o mínimo e nunca convergir.
- Tamanho do lote(Batch Size) – os lotes nos permitem usar a descida gradiente estocástica.
- Valores Menores → menos representativo dos dados.
- Valores Maiores → maior tempo de treinamento.
- O comportamento de segunda ordem da descida de gradiente nos permite ajustar nossa taxa de aprendizado com base na taxa de descida.
- AdaGrad
- RMSProp
- Adam
A razão para o uso de Batch Size é porque se alimentássemos todos os nossos dados em nossa rede neural de uma vez, haveria tantos parâmetros para tentar resolver que seria computacionalmente muito caro para executar a descida de gradiente.
É por isso que precisamos alimentar a rede nos chamados minilotes de dados.
O comportamento de segunda ordem da descida de gradientes permite começar com passos maiores e, em seguida, ir para passos menores.
Adam permite que essa mudança aconteça automaticamente.
Gradientes instáveis / gradiente de desaparecimento
Conforme você aumenta o número de camadas em uma rede, as camadas em direção à entrada serão menos afetadas pelo cálculo do erro que ocorre na saída.
Isso é especialmente verdadeiro se você tiver uma rede neural muito profunda com toneladas de camadas conforme você propaga de volta o gradiente.
Ele vai ficar cada vez menor e é daí que vem o termo gradiente de desaparecimento.
Se você tiver uma rede super profunda, você provavelmente não mudará nenhum dos pesos no início da rede.
Nesses casos, a inicialização e a normalização vai ajudar a mitigar alguns desses problemas.
E de fato, se você tiver uma boa inicialização e normalização, raramente terá que se preocupar com gradientes de desaparecimento.
Gradientes Explosivos
Há também um problema oposto chamado gradientes explosivos.
Ele é mais raro.
Overfitting(sobreajuste ou superajuste) e Underfitting(sub-ajuste)
O sobreajuste é quando o modelo se adequa quase que totalmente aos dados de treino, mas quando recebe um dado novo, ele prevê de forma errada.
É quase como se o modelo decorasse as repostas do conjunto de treino, mas quando se depara com algo que nunca viu antes, não consegue fazer a previsão corretamente.
E sub-ajuste é justamente ao contrário, é quando o modelo não treinou o suficientemente com a base de treino.
Precisamos então achar um equilíbrio.
Existem métodos estatísticos como a regularização L1 e L2 onde a ideia básica é que eles apenas adicionem uma penalidade para pesos maiores no modelo.
Assim, você não acaba recebendo um recurso em seu conjunto de treinamento que realmente tem um grande peso associado a ele ou quando você está em seu conjunto de treinamento que tem um grande peso ligado a ele.
Outra técnica comum é chamada de abandono ou, dropout.
A ideia é remover os neurônios durante o treinamento de forma aleatória.
Então, enquanto a rede está treinando, é escolhido neurônios aleatórios para serem removidos e, dessa forma, a rede não depende muito de um neurônio em particular durante o treinamento.
Isso pode ajudar a mitigar o sobreajuste.
Há outra técnica que é conhecida como expansão de dados, você pode basicamente expandir seus dados adicionando ruído, ou pode inclinar imagens, ou talvez frequências baixas de ruído branco em dados de audio.
Por essa aula é só, na próxima vamos dá uma olhada na base de dados MNIST.
\o/ e até lá!
Voltar para página principal do blog
Todas as aulas desse curso
Aula 17 Aula 19
Meu github:
https://github.com/toticavalcanti
Se gostarem do conteúdo dêem um joinha 👍 na página do Código Fluente no
Facebook
Link do código fluente no Pinterest
Novamente deixo meus link de afiliados:
Hostinger
Digital Ocean
One.com
Obrigado, até a próxima e bons estudos. 😉