Aula 36 – TensorFlow – Keras – Redes Neurais – RNN Chatbot
Aula 36 – TensorFlow – Keras – Redes Neurais – RNN Chatbot
Voltar para página principal do blog
Todas as aulas desse curso
Aula 35 Aula 37

TensorFlow – Keras – Redes Neurais

Pacote Programador Fullstack
Redes Sociais:
Site das bibliotecas
Tensorflow
Keras
Cursos Gratuitos
Digital Innovation
Quer aprender python3 de graça e com certificado? Acesse então:
workover
Para aprender Python do zero, além do curso aqui do código fluente, eu indico também esse curso do Python Academy.

Python Academy
Meus link de afiliados:
Hostinger
Digital Ocean
One.com
Canais do Youtube
Toti:
Toti
Backing Track / Play-Along
Código Fluente
Putz!
Vocal Techniques and Exercises
Fiquem a vontade para me adicionar ao linkedin.
PIX para doações

PIX Nubank
Notebook da aula
Base de dados: human_text.txt e o robot_text.txt
Aula 36 – TensorFlow – Keras – Redes Neurais – RNN Chatbot
O artigo original seguido para essa aula é: Generative chatbots using the seq2seq model! de Dhruvil Shah.
Preparando os dados
Vamos continuar preparando os dados dos diálogos.
Agora teremos que criar listas separadas para sequências de entrada e sequências de saída e também precisaremos criar listas para tokens exclusivos (tokens de entrada e tokens de saída) no conjunto de dados.
Para sequências de destino, ou de saída, adicionaremos ‘<START>‘ no início da sequência e ‘<END>‘ no final da sequência para que nosso modelo saiba onde iniciar e terminar a geração de texto.
Faremos isso conforme mostrado abaixo.
import numpy as np
input_docs = []
target_docs = []
input_tokens = set()
target_tokens = set()
for line in pairs[:400]:
input_doc, target_doc = line[0], line[1]
# Appending each input sentence to input_docs
input_docs.append(input_doc)
# Splitting words from punctuation
target_doc = " ".join(re.findall(r"[\w']+|[^\s\w]", target_doc))
# Redefine target_doc below and append it to target_docs
target_doc = '<START> ' + target_doc + ' <END>'
target_docs.append(target_doc)
# Now we split up each sentence into words and add each unique word to our vocabulary set
for token in re.findall(r"[\w']+|[^\s\w]", input_doc):
if token not in input_tokens:
input_tokens.add(token)
for token in target_doc.split():
if token not in target_tokens:
target_tokens.add(token)
input_tokens = sorted(list(input_tokens))
target_tokens = sorted(list(target_tokens))
num_encoder_tokens = len(input_tokens)
num_decoder_tokens = len(target_tokens)Nota: Estamos pegando apenas os primeiros 400 pares dos 2363 pares, para manter as coisas simples, mas, como resultado, teremos uma precisão muito baixa.
Temos tokens únicos de entrada e saída(alvo) no conjunto de dados.
Agora vamos criar um dicionário de recursos de entrada que armazenará nossos tokens de entrada como pares chave-valor, sendo a palavra a chave e o valor o índice.
Da mesma forma, para tokens alvo, isto é, os de saída, criaremos um dicionário de features alvo.
One-hot
O dicionário de recursos nos ajudará a codificar nossas frases em vetores one-hot.
Afinal, computadores só entendem números.
Codificação One-Hot
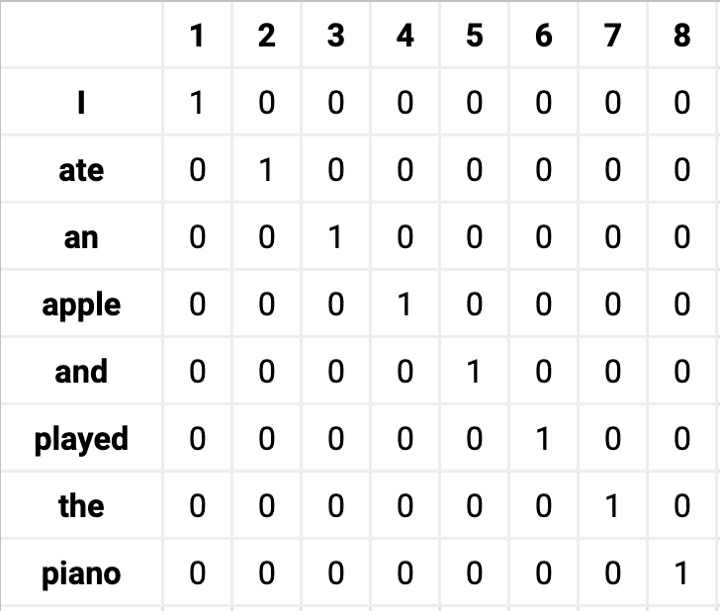
Vamos dar uma olhada na seguinte frase: “I ate an apple and played the piano.“.
Podemos começar indexando a posição de cada palavra no conjunto de vocabulário dado.
Posição de cada palavra no vocabulário
A palavra “I” está na posição 1, então sua representação de vetor one-hot seria [1, 0, 0, 0, 0, 0, 0, 0].
Da mesma forma, a palavra “ate” está na posição 2, então seu vetor one-hot seria [0, 1, 0, 0, 0, 0, 0, 0].
O número de palavras no vocabulário fonte significa o número de dimensões – nesse exemplo temos oito.
A matriz de incorporação one-hot para o texto de exemplo ficaria assim:
one-hot
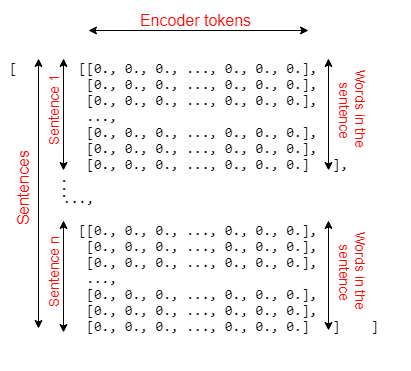
Para obter uma compreensão clara de como as dimensões de encoder_input_data funcionam, veja a figura abaixo. O decoder_input_data e o decoder_target_data também têm as dimensões.
Para decodificar as frases, precisaremos criar o dicionário de recursos reversos que armazena índice como chave e palavra como valor.
input_features_dict = dict(
[(token, i) for i, token in enumerate(input_tokens)])
target_features_dict = dict(
[(token, i) for i, token in enumerate(target_tokens)])
O input_features_dict vai ficar mais ou menos assim:
{…’away’: 89, ‘azov’: 90, ‘b2’: 91, ‘bad’: 92, ‘battery’: 93, ‘be’: 94, …}
O target_features_dict assim:
{…, ‘as’: 90, ‘asimov’: 91, ‘ask’: 92, ‘at’: 93, ‘atlas’: 94, ‘available’: 95, ‘back’: 96, ‘bad’: 97, ‘band’: 98, …}
reverse_input_features_dict = dict(
(i, token) for token, i in input_features_dict.items())
reverse_target_features_dict = dict(
(i, token) for token, i in target_features_dict.items())
O reverse_input_features_dict assim:
{…, 85: ‘australia’, 86: ‘author’, 87: ‘automatically’, 88: ‘available’, 89: ‘away’, 90: ‘azov’, 91: ‘b2’, 92: ‘bad’, 93: ‘battery’, …}
O reverse_target_features_dict assim:
{…, 91: ‘asimov’, 92: ‘ask’, 93: ‘at’, 94: ‘atlas’, 95: ‘available’, 96: ‘back’, 97: ‘bad’, 98: ‘band’, 99: ‘bar’, 100: bartender’, 101: ‘based’, …}
Configuração de treinamento
Para treinar nosso modelo seq2seq, usaremos três matrizes de vetores one-hot:
1 – Dados de entrada do codificador(Encoder input data)
2 – Dados de saída do decodificador(Decoder input data)
3 – Dados de saída do decodificador(Decoder output data)
A razão pela qual estamos usando duas matrizes para o decoder, é um método chamado de aprendizado forçado, ou teacher forcing, que é usado pelo modelo seq2seq durante o treinamento.
Qual é a ideia por trás disso?
Temos um token de entrada do timestep anterior para ajudar o modelo a treinar e chegar ao token alvo atual.
Vamos criar essas matrizes.
#Maximum length of sentences in input and target documents
max_encoder_seq_length = max([len(re.findall(r"[\w']+|[^\s\w]", input_doc)) for input_doc in input_docs])
max_decoder_seq_length = max([len(re.findall(r"[\w']+|[^\s\w]", target_doc)) for target_doc in target_docs])
encoder_input_data = np.zeros(
(len(input_docs), max_encoder_seq_length, num_encoder_tokens),
dtype='float32')
decoder_input_data = np.zeros(
(len(input_docs), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')
decoder_target_data = np.zeros(
(len(input_docs), max_decoder_seq_length, num_decoder_tokens),
dtype='float32')Funçao numpy.zeros()
A função numpy.zeros() retorna uma nova matriz de determinada forma e tipo, onde o valor do elemento é 0.
zeros(shape, dtype=None, order=’C’)
O shape é um int ou tupla de ints que define o tamanho da matriz.
O dtype é um parâmetro opcional com valor padrão sendo float. É usado para especificar o tipo de dados da matriz, por exemplo, int.
O order define se o array multidimensional deve ser armazenado em ordem de linha (estilo C) ou em ordem de coluna (estilo Fortran) na memória.
for line, (input_doc, target_doc) in enumerate(zip(input_docs, target_docs)):
print("Input doc: " + input_doc)
print("Target doc: " + target_doc)
print("Line: " + str(line))
for timestep, token in enumerate(re.findall(r"[\w']+|[^\s\w]", input_doc)):
#Assign 1. for the current line, timestep, & word in encoder_input_data
encoder_input_data[line, timestep, input_features_dict[token]] = 1.
for timestep, token in enumerate(target_doc.split()):
decoder_input_data[line, timestep, target_features_dict[token]] = 1.
if timestep > 0:
decoder_target_data[line, timestep - 1, target_features_dict[token]] = 1.
As linhas:
encoder_input_data[line, timestep, input_features_dict[token]] = 1.
decoder_input_data[line, timestep, target_features_dict[token]] = 1.
Preenche com 1.0 sempre que no input_features_dict[token]] ou no target_features_dict[token]], a palavra, isto é, o token, coincidir com a palavra que está naquela linha iterada na posição específica do timestep.
Por exemplo, linha = 1, timestep = 3 e target_features_dict[“afternoon”], ou seja, target_features_dict ,a posição “afternoon“, vai coincidir, então preenche com 1.0.
decoder_input_data[1, 3, target_features_dict[“afternoon”]] = 1.
Esse print abaixo é do input_doc, do target_doc e do lines.
Target doc: <START> hi there how are you <END>
Line: 0
Input doc: oh thanks i m fine this is an evening in my timezone
Target doc: <START> here is afternoon <END>
Line: 1
Input doc: how do you feel today tell me something about yourself
Target doc: <START> my name is rdany but you can call me dany the r means robot i hope we can be virtual friends <END>
Line: 2
Input doc: how many virtual friends have you got
Target doc: <START> i have many but not enough to fully understand humans beings <START>
Line: 3
Input doc: is that forbidden for you to tell the exact number
Target doc: <START> i ve talked with 143 users counting 7294 lines of text <START>
Line: 4
…