Aula 37 – TensorFlow – Keras – Redes Neurais – RNN Chatbot
Aula 37 – TensorFlow – Keras – Redes Neurais – RNN Chatbot
Voltar para página principal do blog
Todas as aulas desse curso
Aula 36 Aula 38 (Ainda não disponível)

TensorFlow – Keras – Redes Neurais

Pacote Programador Fullstack
Redes Sociais:
Site das bibliotecas
Tensorflow
Keras
Cursos Gratuitos
Digital Innovation
Quer aprender python3 de graça e com certificado? Acesse então:
workover
Para aprender Python do zero, além do curso aqui do código fluente, eu indico também esse curso do Python Academy.

Python Academy
Meus link de afiliados:
Hostinger
Digital Ocean
One.com
Canais do Youtube
Toti
Backing Track / Play-Along
Código Fluente
Putz!
Vocal Techniques and Exercises
Fiquem a vontade para me adicionar ao linkedin.
PIX para doações

PIX Nubank
Notebook da aula
Base de dados: human_text.txt e o robot_text.txt
Aula 37 – TensorFlow – Keras – Redes Neurais – RNN Chatbot
O artigo original seguido para essa aula é: Generative chatbots using the seq2seq model! de Dhruvil Shah.
Configuração do treinamento do Encoder-decoder
O modelo codificador requer uma camada de entrada(encoder_inputs) que define uma matriz para conter os vetores one-hot e uma camada LSTM (Long Short-Term Memory layer) com algum número de estados ocultos.
No processamento de linguagem natural, os vetores one-hot são uma maneira de representar uma determinada palavra em um conjunto de palavras em que 1 indica a palavra atual e 0s indicam todas as outras palavras.
# vetor one-hot da palavra “nice”
# na frase: “Hello chatbot nice to meet you”
[ 0 , 0 , 1 , 0 , 0 , 0 ]
A estrutura do modelo do decodificador é quase a mesma do codificador.
Passamos os dados de estado junto com as entradas do decodificador.
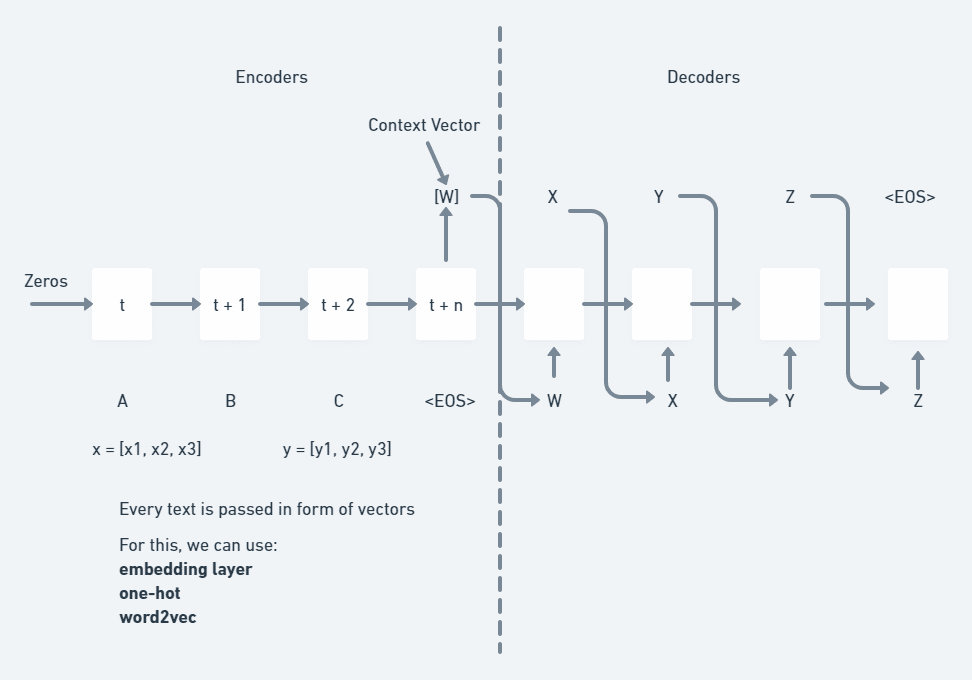
seq2seq
Tensor Keras
Um tensor Keras é um objeto n dimensional, isto é, uma matriz.
Input
Vamos usar o Input() para instanciar um tensor Keras.
Veja um exemplo simples de como funciona.
Se a, b e c são tensores Keras, torna-se possível fazer: model = Model(input=[a, b], output=c)
Long Short-Term Memory
Logo depois do Input() vamos usar a LSTM() importada do keras.layers.
A Long Short-Term Memory, ou LSTM, é uma rede neural recorrente composta por portas internas.
As LSTM são um tipo de rede neural recorrente capaz de aprender a dependência de ordem em problemas de predição de sequência.
Esse é um comportamento necessário em domínios de problemas complexos, como tradução automática, reconhecimento de fala e muito mais.
Ao contrário de outras redes neurais recorrentes, as portas internas permitem que o modelo seja treinado com sucesso usando backpropagation through time, ou BPTT, evitando o problema de desaparecimento de gradientes (vanishing gradients).
Vanishing gradients é o fenômeno que ocorre à medida que mais camadas usando certas funções de ativação são adicionadas às redes neurais, os gradientes da função de perda se aproximam de zero, dificultando o treinamento da rede.
A criação de uma camada de unidades de memória LSTM permite especificar o número de unidades de memória dentro da camada.
Cada unidade ou célula dentro da camada tem um estado de célula interna, geralmente abreviado como “ c ”, e gera um estado oculto, geralmente abreviado como “ h ”.
A API do Keras permite acessar esses dados, que podem ser úteis ou mesmo necessários no desenvolvimento de arquiteturas sofisticadas de redes neurais recorrentes, como o modelo codificador-decodificador.
A Long Short-Term Memory LSTM tem três camadas:
- portão de esquecimento (Forget Gate)
- portão de entrada (Input Gate)
- portão de saída (Output Gate)
O Forget gate decide quanto dos dados anteriores serão esquecidos e quanto dos dados anteriores serão usado nas próximas etapas.
O resultado desta porta está no intervalo entre 0-1, “0” esquece os dados anteriores completamente e “1” usa os dados anteriores totalmente.
O Input Gate adiciona informação útil ao estado da célula.
O Output Gate extrai informação útil do estado da célula e fornece como saída.
Na figura abaixo, é incluído ainda o Input Modulation Gate, ficando com “4 camadas“.
O Input Modulation Gate muitas vezes é considerado como uma subparte do Input Gate e a literatura sobre LSTM raramente menciona o Input Modulation Gate e assume que ele está dentro do portão de entrada.
Ele é usado para modular as informações que o Input Gate escreverá na célula de estado interno, adicionando não linearidade às informações e tornando as informações com média zero .
Célula LSTM:
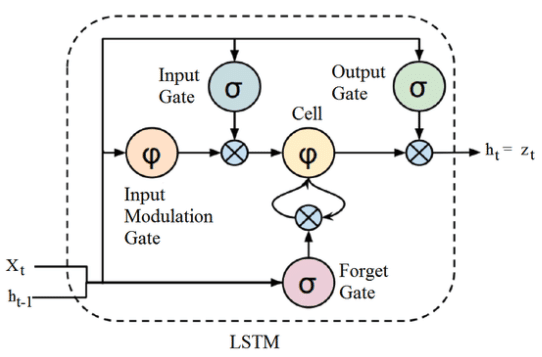
Célula LSTM
RNN
Redes neurais recorrentes são redes com loops.
Elas permitem que as informações persistam.
Uma rede neural recorrente pode ser vista como múltiplas cópias dela mesma, cada uma passando uma mensagem a sua sucessora.
Veja a figura abaixo.
Perceba que se a gente desenrolar o loop a esquerda do igual, vamos ter o que tá na direita:
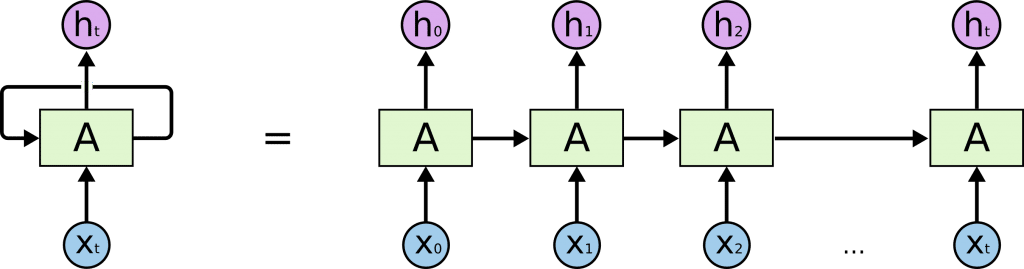
Loop RNN
Por essas características, ela é adequada para classificar, processar e prever séries temporais com intervalos de tempo de duração desconhecida.
Estados e Sequências
Cada célula LSTM produz um estado oculto h de saída para cada entrada.
Podemos acessar a sequência de estado oculto e os estados da célula ao mesmo tempo.
Isso pode ser feito configurando a camada LSTM para retornar sequências e retornar estados.
O None que é o primeiro argumento da tupla que shape recebe, significa que o tamanho da entrada pode ser qualquer número escalar, dessa forma o modelo consegue inferir uma entrada arbitrariamente longa.
Esta dimensão não afeta o tamanho da rede, apenas denota que você é livre para selecionar o comprimento, ou seja, o número de amostras de sua entrada durante o teste.
from tensorflow import keras
from keras.layers import Input, LSTM, Dense
from keras.models import Model
#Dimensionality
dimensionality = 256
#The batch size and number of epochs
batch_size = 10
epochs = 600
#Encoder
encoder_inputs = Input(shape=(None, num_encoder_tokens))
encoder_lstm = LSTM(dimensionality, return_state=True)
encoder_outputs, state_hidden, state_cell = encoder_lstm(encoder_inputs)
encoder_states = [state_hidden, state_cell]
#Decoder
decoder_inputs = Input(shape=(None, num_decoder_tokens))
decoder_lstm = LSTM(dimensionality, return_sequences=True, return_state=True)
decoder_outputs, decoder_state_hidden, decoder_state_cell = decoder_lstm(decoder_inputs, initial_state=encoder_states)
decoder_dense = Dense(num_decoder_tokens, activation='softmax')
decoder_outputs = decoder_dense(decoder_outputs)Construindo e treinando o modelo seq2seq
Uma vez configurada a parte do treinamento, agora vamos criar o modelo seq2seq propriamente dito e treiná-lo com os dados do codificador e do decodificador, conforme mostrado abaixo.
#Model
training_model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
#Compiling
training_model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'], sample_weight_mode='temporal')
#Training
training_model.fit([encoder_input_data, decoder_input_data], decoder_target_data, batch_size = batch_size, epochs = epochs, validation_split = 0.2)
training_model.save('training_model.h5')Aqui, estamos usando rmsprop como otimizador e categorical_crossentropy como função de perda.
Chamamos o método .fit() fornecendo os dados de entrada do codificador e do decodificador (X/input) e os dados alvo do decodificador (Y/label).
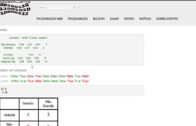
Após o término do treinamento, obtemos uma precisão de treinamento de cerca de 20%.
A razão para essa baixa precisão é que usamos apenas 400 amostras do conjunto de dados.
Se treinado em um conjunto de dados maior, uma maior precisão pode ser alcançada.
Configuração de teste
Agora, para lidar com uma entrada que o modelo não viu, precisaremos de um modelo que decodifique passo a passo em vez de usar o teacher forcing, porque o modelo que criamos só funciona quando a sequência de destino é conhecida.
Na aplicação de chatbot generativo não saberemos qual será a resposta gerada para a entrada que o usuário passar.
Para isso, teremos que construir um modelo seq2seq em peças individuais.
Vamos primeiro construir um modelo codificador com as entradas do codificador e estados de saída do codificador.
Faremos isso com a ajuda do modelo previamente treinado.
from keras.models import load_model
training_model = load_model('training_model.h5')
encoder_inputs = training_model.input[0]
encoder_outputs, state_h_enc, state_c_enc = training_model.layers[2].output
encoder_states = [state_h_enc, state_c_enc]
encoder_model = Model(encoder_inputs, encoder_states)Encoder input
training_model.input[0]
<KerasTensor: shape=(None, None, 981) dtype=float32 (created by layer ‘input_1‘)>
Decoder input
training_model.input[1]
<KerasTensor: shape=(None, None, 1003) dtype=float32 (created by layer ‘input_2‘)>
training_model.layers[0].output
<KerasTensor: shape=(None, None, 981) dtype=float32 (created by layer ‘input_1‘)>
training_model.layers[1].output
<KerasTensor: shape=(None, None, 1003) dtype=float32 (created by layer ‘input_2‘)>
training_model.layers[2].output
[
<KerasTensor: shape=(None, 256) dtype=float32 (created by layer ‘lstm‘)>,
<KerasTensor: shape=(None, 256) dtype=float32 (created by layer ‘lstm‘)>,
<KerasTensor: shape=(None, 256) dtype=float32 (created by layer ‘lstm‘)>
]
O training_model.layers[3].output
[
<KerasTensor: shape=(None, None, 256) dtype=float32 (created by layer ‘lstm_1‘)>,
<KerasTensor: shape=(None, 256) dtype=float32 (created by layer ‘lstm_1‘)>,
<KerasTensor: shape=(None, 256) dtype=float32 (created by layer ‘lstm_1‘)>
]
O training_model.layers[4].output
<KerasTensor: shape=(None, None, 1003) dtype=float32 (created by layer ‘dense‘)>
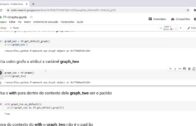
Em seguida, precisaremos criar espaços reservados para os estados de entrada do decodificador, pois não sabemos o que precisamos decodificar ou qual estado oculto obteremos.
latent_dim = 256
decoder_state_input_hidden = Input(shape=(latent_dim,))
decoder_state_input_cell = Input(shape=(latent_dim,))
decoder_states_inputs = [decoder_state_input_hidden, decoder_state_input_cell]decoder_state_input_hidden
<KerasTensor: shape=(None, 256) dtype=float32 (created by layer ‘input_3‘)>
decoder_state_input_cell
<KerasTensor: shape=(None, 256) dtype=float32 (created by layer ‘input_4‘)>
decoder_states_inputs
[
<KerasTensor: shape=(None, 256) dtype=float32 (created by layer ‘input_3‘)>,
<KerasTensor: shape=(None, 256) dtype=float32 (created by layer ‘input_4‘)>
]
Agora vamos criar novos estados e saídas do decodificador com a ajuda do decodificador LSTM e da camada Densa que treinamos anteriormente.
decoder_outputs, state_hidden, state_cell = decoder_lstm(decoder_inputs, initial_state=decoder_states_inputs)
decoder_states = [state_hidden, state_cell]
decoder_outputs = decoder_dense(decoder_outputs)Finalmente, temos a camada de entrada do decodificador, os estados finais do codificador, as saídas do decodificador da camada Densa do decodificador e os estados de saída do decodificador que é a memória durante o loop da rede de uma palavra para a próxima.
Podemos reunir tudo isso agora e configurar o modelo do decodificador conforme mostrado abaixo.
decoder_model = Model([decoder_inputs] + decoder_states_inputs, [decoder_outputs] + decoder_states) decoder_inputs
<KerasTensor: shape=(None, None, 1003) dtype=float32 (created by layer ‘input_2’)>
decoder_states_inputs
[
<KerasTensor: shape=(None, 256) dtype=float32 (created by layer ‘input_3’)>,
<KerasTensor: shape=(None, 256) dtype=float32 (created by layer ‘input_4’)>
]
decoder_outputs
<KerasTensor: shape=(None, None, 1003) dtype=float32 (created by layer ‘dense’)>
decoder_states
[
<KerasTensor: shape=(None, 256) dtype=float32 (created by layer ‘lstm_1’)>,
<KerasTensor: shape=(None, 256) dtype=float32 (created by layer ‘lstm_1’)>
]
decoder_model
<keras.engine.functional.Functional at 0x7f2beca99a30>