Aula 43 – Redes Neurais – Modelos de Difusão Estável
Aula 43 – Redes Neurais – Modelos de Difusão Estável
Voltar para página principal do blog
Todas as aulas desse curso
Aula 42 Aula 44

TensorFlow – Keras – Redes Neurais

Pacote Programador Fullstack
Redes Sociais:
Site das bibliotecas
Tensorflow
Keras
Cursos Gratuitos
Digital Innovation
Quer aprender python3 de graça e com certificado? Acesse então:
workover
Meus link de afiliados:
Hostinger
Digital Ocean
One.com
Canais do Youtube
Toti
Lofi Music Zone Beats
Backing Track / Play-Along
Código Fluente
Putz!
Vocal Techniques and Exercises
Fiquem a vontade para me adicionar ao linkedin.
PIX para doações

PIX Nubank
Links da Aula
Github do FurkanGozukara, autor do notebook dessa aula.
Links Para Explorar Prompts e Testar
https://mpost.io/top-50-text-to-image-prompts-for-ai-art-generators-midjourney-and-dall-e/
https://prompthero.com/stable-diffusion-prompts
https://www.fotor.com/blog/stable-diffusion-prompts/
Aula 43 – Redes Neurais – Modelos de Difusão Estável
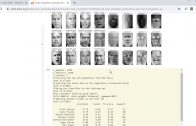
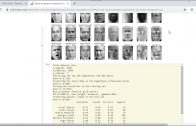
Modelos de Difusão Estável Para Geração de Imagem Através de Prompt de Texto
Introdução
Os modelos de difusão estável(Stable Diffusion) representam uma abordagem avançada de aprendizado de máquina que se tornou proeminente no campo de geração de imagens através de prompt de texto.
Eles oferecem uma forma inovadora de criar imagens bem realistas a partir de um conjunto de dados e através de uma técnica chamada “difusão estável”.
Nesta aula, vamos explorar o conceito por trás dos modelos de difusão estável e entender como eles são aplicados na geração de texto para imagem.
1. O que são Modelos de Difusão Estável?
Os modelos de difusão estável são uma classe de modelos generativos que visam criar distribuições de probabilidade complexas e multifacetadas.
Em vez de gerar diretamente uma amostra completa de dados, como uma imagem ou um texto, eles operam em um espaço latente (também conhecido como espaço oculto) onde a informação é gradualmente difundida ao longo de um processo chamado “difusão estável“.
2. A Técnica de Difusão Estável
A difusão estável é um processo estocástico em que cada ponto de dados no espaço é gradualmente transformado em uma amostra de dados reais.
O modelo usa uma cadeia de transformações probabilísticas para atingir esse objetivo.
3. Aplicação na Geração de Texto para Imagem
A aplicação dos modelos de difusão estável na geração de texto para imagem envolve duas etapas principais:
a) Geração de Texto para Imagens: Nesta etapa, o modelo recebe um prompt de texto como entrada.
A partir desse texto, os modelos de difusão estável utilizam um “modelo base” para mapear o texto em um conjunto de vetores que representam o conteúdo do texto.
Esses vetores são essenciais para a criação da imagem relacionada ao prompt.
b) Transformação de Vetores em Imagens: Na segunda etapa, é utilizado um “modelo de alta resolução” especializado para transformar os vetores gerados na etapa anterior em imagens de alta qualidade.
Aqui, a técnica SDEdit é empregada, permitindo que os vetores influenciem a geração de imagens, garantindo que as imagens geradas sejam condicionadas ao texto fornecido.
SDEdit (Stochastic Diffusion Editing) é uma técnica especializada utilizada no contexto do Stable Diffusion.
O SDEdit é uma das etapas do processo de geração de texto em imagem, e é responsável por transformar os vetores latentes (representações numéricas do texto) em imagens de alta qualidade e realismo.
Essa técnica permite que os vetores latentes influenciem a geração das imagens, garantindo que as imagens geradas estejam condicionadas ao texto fornecido no prompt.
O SDEdit atua como um “editor estocástico“, combinando os vetores latentes com o ruído inicial e aplicando transformações probabilísticas para criar a imagem final de maneira coerente e semelhante ao texto solicitado.
Em resumo, o SDEdit é um componente crucial do processo de Stable Diffusion que permite que os vetores latentes sejam traduzidos em imagens realistas e de alta qualidade, tornando possível a criação de arte digital com base em prompts de texto.
O Termo Latente no Contexto do Stable Diffusion
No contexto do Stable Diffusion, “Latente” refere-se a uma representação numérica compacta e oculta dos dados de entrada (por exemplo, o texto do prompt).
Essa representação é criada pelo modelo base e usada para gerar a imagem final através do modelo de alta resolução.
Os vetores latentes são como “códigos” que capturam as informações essenciais do texto e guiam a criação da imagem correspondente.
4. Benefícios dos Modelos de Difusão Estável na Geração de Imagem
- Flexibilidade: Os modelos de difusão estável têm a capacidade de gerar imagens realistas com base em prompts de texto variados, possibilitando uma ampla gama de aplicações criativas e artísticas.
- Controle: A técnica de difusão estável permite que os usuários controlem características específicas da imagem gerada, possibilitando a criação de imagens personalizadas e customizadas.
- Geração Amostral: Os modelos de difusão estável são capazes de gerar múltiplas amostras condicionadas ao mesmo texto, o que permite uma exploração mais ampla do espaço de possibilidades.
Explicação Metafórica
Imagine o Stable Diffusion como um “artista plástico bem criativo e mágico“.
Ele recebe um pedido especial (o prompt de texto) e trabalha em duas etapas para transformar esse pedido em uma arte em forma de imagem, surpreendente.
Etapa 1: Geração de Vetores Latentes
O artista começa usando um “modelo base” para transformar o prompt de texto em vetores latentes.
Os vetores latentes são como “pequenos ingredientes mágicos” que representam o conteúdo do texto de maneira especial.
Cada palavra ou frase no prompt é convertida em um desses ingredientes.
Imagine que o prompt seja “um gato voando no espaço“.
O modelo base transforma cada palavra em vetores latentes, como “vetor_gato“, “vetor_voando“, “vetor_espaco“, e assim por diante.
Esses vetores contêm informações sobre o que é um gato, como voar e o espaço.
Etapa 2: Transformação dos Vetores em Imagem
Aqui é onde o verdadeiro truque mágico artístico acontece!
O artista mágico agora usa um “modelo de alta resolução” para transformar os vetores latentes gerados na primeira etapa em uma imagem de alta qualidade.
Esse modelo é especializado em “desenhar” imagens baseadas nos vetores latentes.
Ele usa os vetores como direções e guias para criar cada parte da imagem.
O truque é que, usando técnicas avançadas de “SDEdit“, os vetores influenciam a geração da imagem, garantindo que ela seja exatamente o que o prompt pediu.
Os vetores latentes “vetor_gato“, “vetor_voando” e “vetor_espaco” vão dizer ao modelo como desenhar um gato voando no espaço!
O Toque Final: Do Ruído à Imagem
Você pode se perguntar como o modelo consegue realmente criar a imagem a partir de apenas vetores e texto.
Aqui entra a mágica final!
No início, a imagem é apenas um monte de “ruído”, como uma tela em branco.
Mas à medida que o artista aplica suas técnicas misteriosas, os vetores latentes começam a interagir com o ruído e, aos poucos, a imagem ganha vida.
Como um quadro sendo pintado, o modelo preenche cada pixel da imagem usando as informações dos vetores.
Aos poucos, o ruído mais absoluto é transformado em uma imagem impressionante do gato voando no espaço!
E assim, o modelo de Stable Diffusion transforma um simples prompt de texto em uma imagem única e criativa.
É como se o artista mágico tivesse capturado sua imaginação e a colocado em uma obra de arte digital!
Essa é a magia do Stable Diffusion na geração de texto para imagem.
Conclusão
Os modelos de difusão estável representam um avanço significativo na geração de texto para imagem, possibilitando a criação de conteúdo realista e personalizado com base em prompts de texto.
A abordagem de difusão estável oferece controle e flexibilidade, tornando esses modelos valiosos em aplicações criativas, educacionais e de pesquisa.
No entanto, é importante considerar as limitações e vieses desses modelos, bem como a ética e a responsabilidade em seu uso, para garantir que eles sejam aplicados de forma responsável e consciente.
Links da Aula
Github do FurkanGozukara, autor do notebook dessa aula.