Aula 47 – Redes Neurais – RAG (Retrieval-Augmented Generation)
Aula 47 – Redes Neurais – RAG (Retrieval-Augmented Generation)
Voltar para página principal do blog
Todas as aulas desse curso
Aula 46 Aula 48

TensorFlow – Keras – Redes Neurais

Pacote Programador Fullstack
Redes Sociais:
Site das bibliotecas
Tensorflow
Keras
Cursos Gratuitos
Digital Innovation
Quer aprender python3 de graça e com certificado? Acesse então:
workover
Meus link de afiliados:
Hostinger
Digital Ocean
One.com
Canais do Youtube
Toti
Lofi Music Zone Beats
Backing Track / Play-Along
Código Fluente
Putz!
Vocal Techniques and Exercises
Fiquem a vontade para me adicionar ao linkedin.
PIX para doações

PIX Nubank
Aula 47 – Redes Neurais – RAG (Retrieval-Augmented Generation)
RAG (Retrieval-Augmented Generation)
RAG, ou Geração Aumentada por Recuperação, é uma abordagem que combina técnicas de recuperação de informações (retrieval) e geração de linguagem natural.
O RAG utiliza modelos de recuperação para buscar informações relevantes em grandes conjuntos de dados, como documentos ou passagens de texto.
Em seguida, integra essas informações recuperadas em um modelo de geração de linguagem para produzir respostas mais precisas e contextualmente relevantes.
Importância do RAG
Considere que o ChatGPT só permite no máximo prompts com 2048 caracteres, por exigir mais processamento, memória, além da maior complexidade, etc. O RAG é uma técnica que torna possível você ter um contexto muito maior, tornando possível você alimentar o contexto com um livro, ou vários, com muito mais do que 2048 caracteres.
A relevância do RAG está na melhoria da capacidade de resposta de modelos de linguagem por meio de aprendizado ativo.
As respostas se tornam mais contextualizadas, como o contexto fecha mais o escopo, diminui as alucinações do modelo.
Trata-se de construir uma estratégia de IA para a empresa, para o negócio, etc. E com isso evitar exposição de dados sensíveis e críticos, além de não ficar dependente de empresas terceiras como a OpenAI.
A ideia é trazer a IA para a empresa e não levar a empresa para uma IA fora, de terceiros, onde você não controla quase nada.
Arquitetura
A arquitetura RAG é frequentemente aplicada em sistemas de resposta a perguntas, onde a recuperação de informações é crucial para garantir que as respostas geradas sejam precisas e baseadas em evidências.
Essa abordagem ajuda a superar limitações associadas apenas a modelos de geração, permitindo que o sistema consulte fontes externas durante o processo de resposta.
O RAG busca combinar o poder de recuperação de informações com a capacidade de geração de linguagem natural, resultando em sistemas mais robustos e contextualmente conscientes.
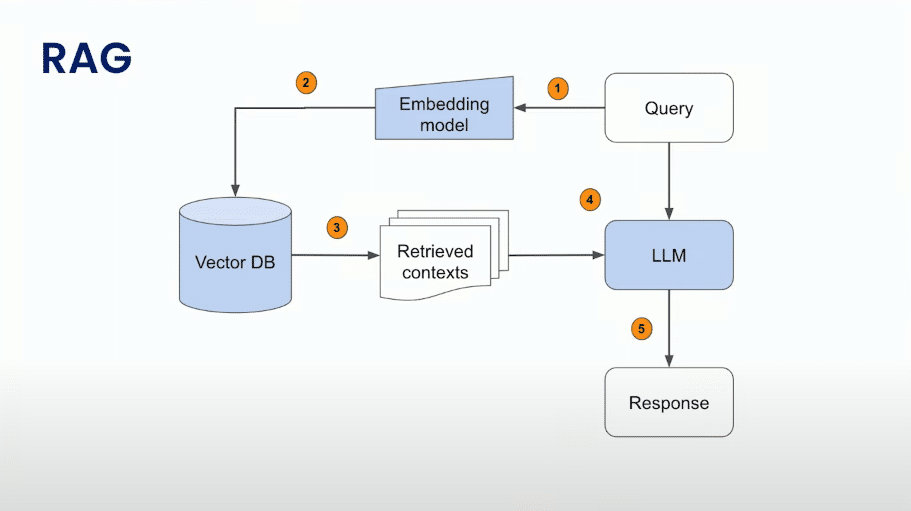
Rag
Explicação da Figura Acima
Query: O processo começa com uma consulta (query). Essa consulta pode ser uma solicitação ou pergunta que precisa ser respondida.
Embedding Model: A consulta é passada para um modelo de incorporação (embedding model). O modelo de incorporação é responsável por converter a consulta em uma representação numérica, muitas vezes chamada de vetor de incorporação, que captura o significado semântico da consulta.
Vector DB: O vetor de incorporação resultante da etapa anterior é então usado para consultar um banco de dados vetorial (Vector DB). Este banco de dados contém representações vetoriais de itens ou contextos relevantes para as consultas.
Retrieved Contexts: O Vector DB retorna contextos relevantes com base na consulta, são os “Retrieved Contexts“. Esses contextos são extraídos do banco de dados com base na similaridade com o vetor de incorporação da consulta.
LLM: Os contextos recuperados são alimentados em um modelo grande de linguagem (LLM). Um modelo de linguagem grande geralmente refere-se a um modelo de linguagem treinado em uma grande quantidade de dados e capaz de gerar texto coerente e contextualmente relevante.
Response: O resultado final é a resposta gerada pelo modelo de linguagem. Esta resposta é então apresentada como o resultado final da consulta original.
Resumindo, o fluxo começa com a consulta, passa por etapas de processamento que envolvem modelos de incorporação, consultas a um banco de dados vetorial, recuperação de contextos relevantes e finalmente, gera uma resposta através de um modelo de linguagem grande.
Embeddings
O vetor resultante que sai de um modelo de incorporação permite compará-lo com outros dados passados pelo mesmo modelo de incorporação(embeddings).
Isto é útil no contexto de LLMs, pois essas incorporações podem atuar como representações de conhecimento que podem ser pesquisadas quando um usuário consulta o LLM.
Você pode adicionar novos dados nos quais o modelo não foi treinado e podem ser anexados como contexto a uma consulta de usuários em um LLM.
Embedding Space
O espaço de incorporação (embedding space) é um espaço matemático onde palavras ou conceitos são representados como vetores.
Esses vetores capturam as relações semânticas e sintáticas entre as palavras.
Em um espaço de incorporação bem projetado, palavras com significados semelhantes estão próximas umas das outras, enquanto palavras com significados diferentes estão mais distantes.
Vector Embedding
A incorporação vetorial (vector embedding) é uma técnica que converte palavras ou conceitos em vetores numéricos em um espaço de incorporação.
Cada dimensão desse vetor representa uma característica específica.
O gráfico abaixo mostra a representação do Vector Embedding de 7D em um espaço X – Y, isto é, 2D.
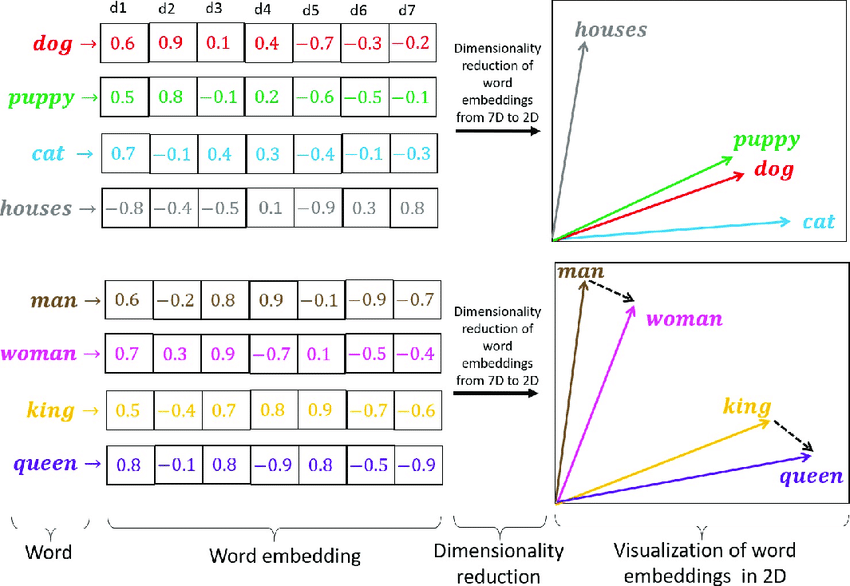
Espaço de Incorporação (Embeddings)
A figura mostra as palavras “dog” e “puppy” próximas, indicando que elas têm uma relação próxima no significado.
A palavra “cat” está um pouco mais distante, sugerindo que tem uma relação de significado um pouco diferente.
“Houses” está mais distante, indicando uma diferença maior de significado.
A representação visual ilustra a redução de uma representação de alta dimensão (7D) para uma representação bidimensional (2D).
No outro exemplo, “Man” e “woman” estão próximos, mas, mais na direção do eixo Y, sugerindo uma relação de gênero.
“King” e “queen” estão mais abaixo, porém, mais próximos ao eixo X, indicando uma relação de realeza.
Novamente, a figura ilustra a redução de uma representação de alta dimensão (7D) para uma representação bidimensional (2D)
Cada etapa contribui para a compreensão e contextualização da consulta, resultando em uma resposta mais informada e relevante.
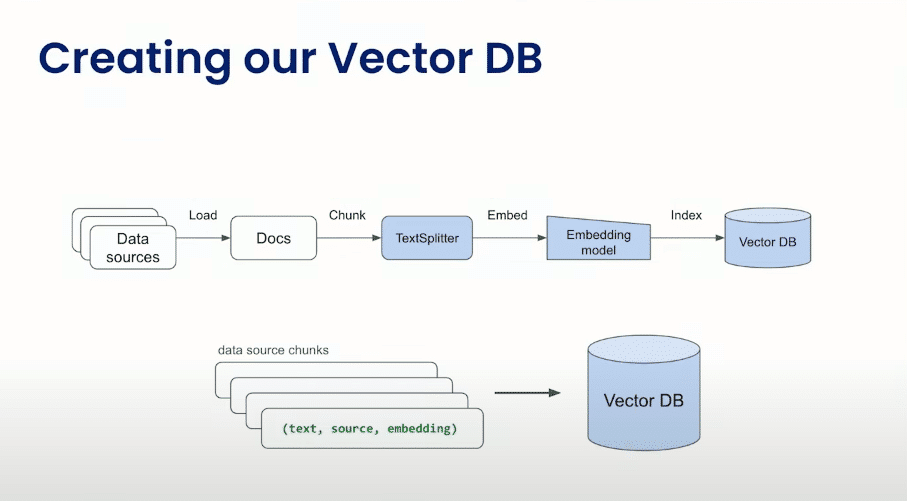
Vector DB
Data Sources: Dados são provenientes de fontes diversas.
Load Docs: Os documentos são carregados.
Chunk (Text Splitter): Os documentos são divididos em partes menores, conhecidas como “chunks“, possivelmente usando estratégias experimentais para otimizar a representação dos dados.
Embedding Model: Cada “chunk” de texto é então incorporado, convertido para uma representação numérica, por um modelo de incorporação (Embedding Model).
Index VectorDB: Os vetores incorporados são indexados no VectorDB para possibilitar consultas eficientes.
Data Source Chunks: Chunks de dados são fornecidos ao VectorDB.
Vector DB: Consultas são realizadas no VectorDB, possivelmente para recuperar informações relevantes com base nos chunks fornecidos.
Retrieval
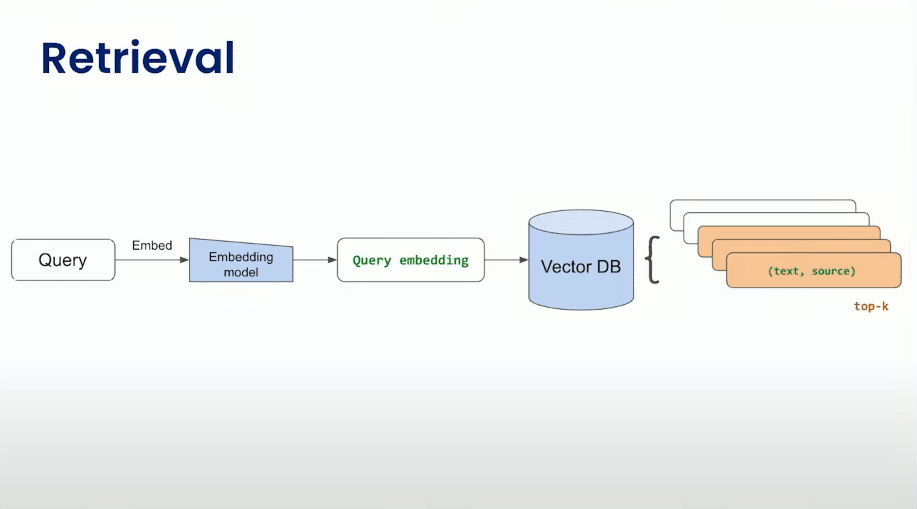
Retrieval
Query: Inicia com uma consulta (query), que é uma pergunta ou solicitação de informação.
Embedding Model: A consulta é então processada pelo modelo de incorporação (Embedding model). Esse modelo converte a consulta de texto em um vetor de incorporação, que é uma representação numérica que captura o significado semântico da consulta.
Query Embedding: O resultado da incorporação é o vetor de incorporação da consulta, representando sua semântica de forma numérica.
VectorDB: O vetor de incorporação da consulta é usado para consultar um VectorDB. Este banco de dados contém vetores incorporados de diversos “chunks” de texto, possivelmente documentos inteiros ou partes significativas de documentos.
Top-K Chunks (Text, Source): Com base na consulta, o VectorDB retorna os principais “chunks” relevantes, representados por pares de texto e fonte (source). O número “K” representa a quantidade de “chunks” retornados, sendo os mais relevantes de acordo com a similaridade com o vetor de incorporação da consulta.
Generation
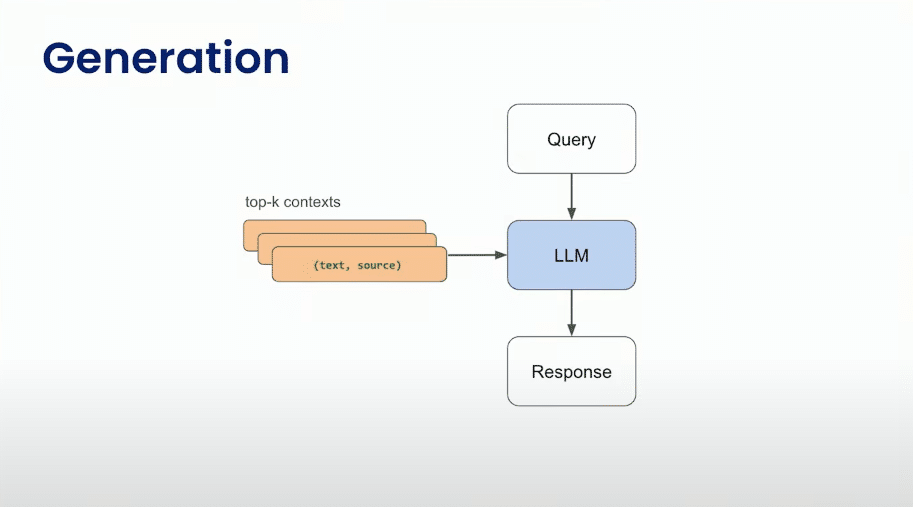
Generation
Query: A consulta original é o ponto de partida.
Top-K Chunks (Text, Source): Os principais “chunks” relevantes, obtidos a partir do VectorDB com base na consulta, são considerados.
Uso da Query e Chunks: Tanto a consulta original quanto os principais “chunks” relevantes são fornecidos como entrada para um Modelo(LLM).
LLM: O LLM utiliza essa entrada para gerar uma resposta significativa e contextualmente relevante.
Response: A resposta gerada pelo LLM é a saída final do processo.
Estrutura – Reação, Reflexão e Ação (React, Reflect, Act)
A abordagem React, Reflect, Act (Reagir, Refletir, Agir) é um framework que visa avaliar e aprimorar a capacidade de resposta de modelos de linguagem, como o GPT-4, Falcon-180B, Llama 2, Claude 2, etc.
Digamos que você tem uma empresa com mais ou menos 10.000 contratos, com modelos LLMs e RAG, você pode integrar os documentos da empresa, fazer análise de contratos, gerenciamento de conhecimento, pesquisa financeira, você pode facilmente extrair respostas sobre esse documentos, etc.
Privacidade e Sensibilidade dos Dados do Negócio
No contexto de uma empresa, de um negócio, de um governo, em geral é preferível que você tenha seu próprio LLM, do que usar serviços de terceiros, como o ChatGPT, Bard, etc.
Não é aconselhável, por razões óbvias, expor dados sensíveis e críticos de empresas, negócios, governos, dados de clientes, etc.
A gestão interna desses modelos não apenas proporciona maior controle sobre a segurança dos dados, mas também minimiza as preocupações relacionadas à confidencialidade e conformidade.
Ao adotar uma abordagem autônoma, as empresas podem implementar medidas personalizadas de segurança, adaptadas às suas necessidades específicas.
Essa autonomia se traduz em uma camada adicional de proteção, especialmente quando lidamos com informações sensíveis e estratégicas.
Desafios de implementação em uma empresa real
A implementação do RAG em uma empresa real pode enfrentar uma série de desafios, incluindo:
- A necessidade de um grande conjunto de dados de treinamento.
- O modelo de recuperação e o modelo de geração precisam ser treinados em um grande conjunto de dados de texto e código e isso pode ser um desafio para empresas que não têm acesso a esses dados.
- A necessidade de um banco de dados eficiente para armazenar as informações recuperadas para que o sistema possa responder às consultas rapidamente.
- A necessidade de um modelo de geração robusto que precisa ser capaz de gerar texto que seja preciso, relevante e criativo.
- A necessidade de uma cultura de inovação. A implementação do RAG requer uma cultura de inovação na empresa. A empresa precisa estar disposta a experimentar novas tecnologias e a aprender com os erros.
- A necessidade de um suporte de gerenciamento. A implementação do RAG requer o apoio do gerenciamento da empresa. O gerenciamento precisa estar disposto a investir no desenvolvimento e na implementação do sistema.
Aplicação e Benefício
As empresas precisam muitas vezes resumir uma enorme pilha de contratos ou analisá-lo, tentar extrair valor deles, insights que podem ajudar a empresa.
Em geral são documentos com números, nomes e terminologias.
O modelo acaba oferecendo uma variedade de controles, marcadores numéricos, de sequência.
Você consegue fazer perguntas como: quero os 5 contratos que…, quero que você resuma isso em 25 palavras, acima desse limite, esse parâmetro está nessa área ou naquela outra?
O treinamento yes/no é muito importante no ajuste fino, ou seja, no fine-tuning que se faz para o RAG.
Tarefas Chave
- Extração chave-valor
- resposta a perguntas
- resumos
- reconhecimento de tipos de valor
- categorização booleana
- respostas resumidas
- não encontrado
Baseado em Fatos
O fato do modelo ser especializado a partir de documentos que o alimentaram, faz com que diminua muito a alucinação, no contexto em que foi treinado.