Aula 48 – Redes Neurais – RAG Avançado com Llamaindex & OpenAI GPT
Aula 48 – Redes Neurais – RAG Avançado com Llamaindex & OpenAI GPT
Voltar para página principal do blog
Todas as aulas desse curso
Aula 47 Aula 49

TensorFlow – Keras – Redes Neurais

Pacote Programador Fullstack
Redes Sociais:
Site das bibliotecas
Tensorflow
Keras
Cursos Gratuitos
Digital Innovation
Quer aprender python3 de graça e com certificado? Acesse então:
workover
Meus link de afiliados:
Hostinger
Digital Ocean
One.com
Canais do Youtube
Toti
Lofi Music Zone Beats
Backing Track / Play-Along
Código Fluente
Putz!
Vocal Techniques and Exercises
Fiquem a vontade para me adicionar ao linkedin.
PIX para doações

PIX Nubank
Links da Aula:
Aula baseada nesse Vídeo do canal @hubel-labs.
Notebook da aula: Google Colab
Aula 48 – Redes Neurais – RAG Avançado com Llamaindex & OpenAI GPT
Visão teórica do que será visto no código do notebook.
documents = SimpleDirectoryReader("./my_data/").load_data()

Carregando os dados
Os Odjetos Documentos são passados para análise nos nós.
Os “nós” são unidades de processamento dentro da rede neural que trabalham para converter os dados de entrada, neste caso, os chunks de documentos em representações vetoriais, conhecidas como embeddings.
# create the sentence window node parser w/ default settings
sentence_node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text"
)
base_node_parser = SentenceSplitter())
Análise realizada pelos nós
Cria os vetores de índices, isto é, os embeddings.
ctx_sentence = ServiceContext.from_defaults(llm=llm, embed_model=OpenAIEmbedding(embed_batch_size=50), node_parser=sentence_node_parser)
ctx_base = ServiceContext.from_defaults(llm=llm, embed_model=OpenAIEmbedding(embed_batch_size=50), node_parser=base_node_parser)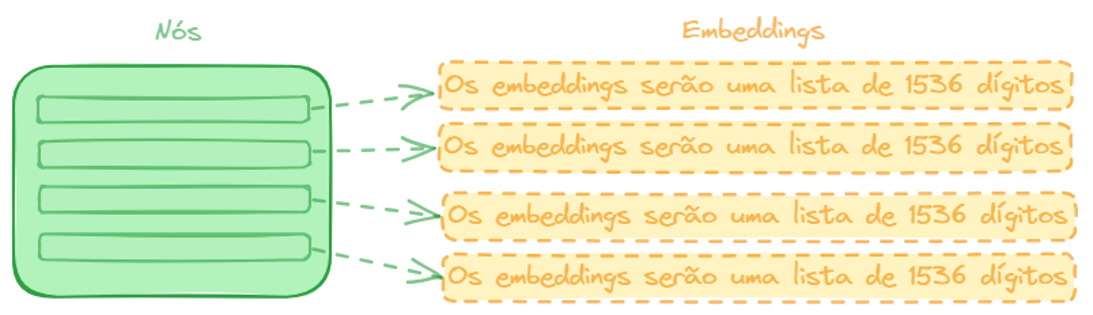
Embeddings, ou seja, vetores de índices.
Embeddings
No caso da OpenAI, o tamanho do embeddings é 1536, mas, esse número depende de cada modelo.
Janela de Contexto
Porque não passamos toda a base de conhecimento de uma só vez?
Por causa da limitação da janela de contexto.
Tokens
Tanto o GPT4 como o Gemini, a janela de contexto é de 32.000 tokens.
O GPT4 turbo é de 128.000 tokens.
A cobrança $ dos serviços é por token.
Tokens não são necessariamente palavras individuais, nem caracteres específicos.
Eles podem ser ambos ou algo intermediário, dependendo do contexto.
No processamento de linguagem natural (NLP), um token é uma unidade de texto que foi segmentada para ser analisada.
Processamento de linguagem natural (NLP)
O Processamento de Linguagem Natural (NLP) lida com a interação entre computadores e humanos através da linguagem.
Aqui estão os processos básicos de NLP que ajudam os computadores a entender nossa linguagem:
Tokenização: É como dividir um bolo em pedaços. Cada palavra ou pontuação em uma frase é um pedaço que o computador analisa separadamente.
Stemming: Imagine ter várias formas da palavra “andar” como “andando”, “andou”, “andará”. O processo de stemming corta as partes variáveis, deixando apenas a base, como “and”. Nem sempre essa base é uma palavra real, mas é suficiente para o computador entender a ação principal.
Lemmatization: Este é um pouco mais sofisticado. Em vez de apenas cortar, lemmatization transforma palavras em suas formas de dicionário. “Sou”, “é”, “são” todos viram “ser”. É como se o computador usasse um dicionário para entender que diferentes palavras podem significar a mesma coisa.
Remoção de Stop Words: Algumas palavras são como tempero demais na comida, podem sobrecarregar o computador com informação desnecessária. Palavras como “e“, “ou” e “mas” são removidas para que o computador se concentre no que é mais importante.
POS Tagging: Aqui, cada palavra recebe um rótulo, como “verbo“, “substantivo” ou “adjetivo“. É como identificar se algo é um objeto, uma ação ou uma descrição.
NER (Named Entity Recognition): O computador aprende a identificar nomes de pessoas, lugares ou empresas. É como apresentar os convidados em uma festa, dizendo quem é quem.
Análise de Sentimentos: É a habilidade do computador de detectar se você está feliz, triste ou irritado com base no que você escreve.
Modelo Simples (Vanilla Model)
Em um modelo simples de RAG, podemos dividir os documentos em pedaços como mostrados na figura abaixo (Embeddings, ou seja, vetores de índices).
Nesse caso, a gente pode se deparar com sobreposição de documentos.
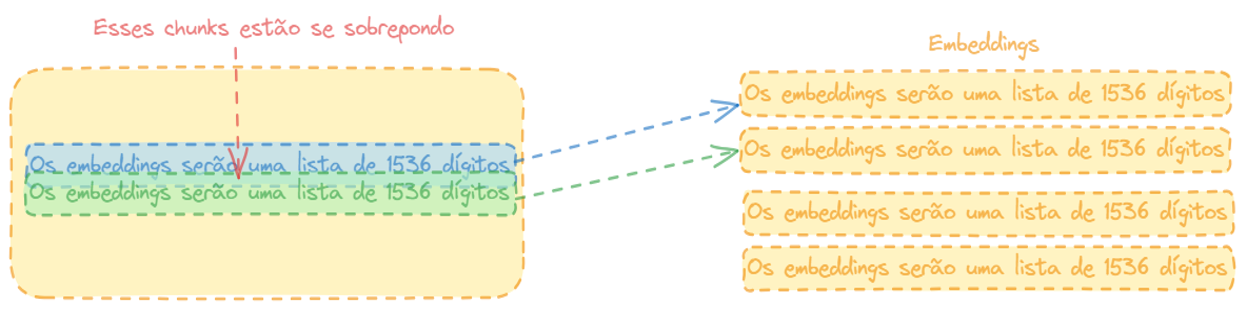
Sobreposição de chunks em modelos simples
Contexto: A intersecção entre chunks pode ser utilizada para manter o contexto que poderia ser perdido se um documento fosse estritamente dividido em partes sem sobreposição. Isso é particularmente importante em textos onde a compreensão do contexto é crucial para interpretar corretamente a informação.
Definição do Tamanho dos Chunks: Decidir sobre o tamanho dos chunks é uma parte crucial do design de um sistema RAG. Chunks muito grandes podem ser problemáticos para processar, enquanto chunks muito pequenos podem não conter informação contextual suficiente.
Grau de Intersecção: O grau de intersecção entre os chunks precisa ser definido. Uma intersecção maior pode ajudar a preservar o contexto, mas também pode levar a redundâncias. Por outro lado, uma intersecção menor pode reduzir a redundância, mas aumenta o risco de perder informações contextuais importantes.
Recuperação de Janela de Frase(Sentence Window Retrieval )
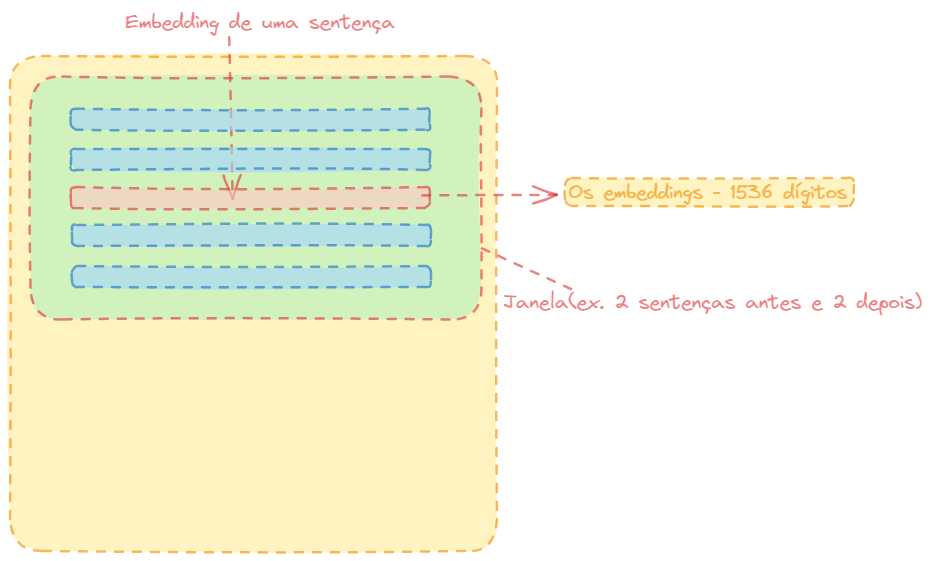
Recuperação de Janela de Frase
Pense como se tivesse fazendo uma pesquisa semântica em um nível mais granular comparando sentenças.
Mas, assim que encontrar uma ocorrência em vez de retornar apenas aquela sentença, você definirá uma janeça ao redor dela.
Você pode dizer X números de tokens antes e depois.
Com isso, ganha-se mais precisão na hora de gerar os embeddings na pesquisa semântica, capturando o contexto no entorno da sentença.
Sentence Window Retrieval é uma técnica usada em processamento de linguagem natural (NLP) e sistemas de recuperação de informações.
A ideia por trás dessa técnica é simples e eficaz:
Foco na Sentença: Em vez de considerar um documento inteiro ou grandes blocos de texto, a técnica se concentra em sentenças individuais ou em pequenas janelas de sentenças.
Janela de Busca: Uma “janela” é definida em torno de cada sentença. Isso significa que, além da sentença principal, algumas sentenças antes e/ou depois dela também são consideradas. Por exemplo, se a janela for definida como 1, para cada sentença, a sentença anterior e a próxima também são incluídas na análise.
Recuperação de Informação: Quando uma consulta de pesquisa é feita, o sistema busca nas janelas de sentenças em vez de em documentos inteiros. Isso permite encontrar as informações mais relevantes e contextuais, mesmo que essas informações estejam espalhadas por diferentes partes do documento.
Eficiência e Precisão: Essa abordagem pode ser mais eficiente do que processar documentos inteiros e, frequentemente, leva a resultados mais precisos, pois a informação relevante é geralmente concentrada em torno de sentenças específicas dentro de um contexto maior.
Sentence Window Retrieval é particularmente útil em grandes conjuntos de dados ou documentos, onde a informação precisa ser encontrada rapidamente e de forma precisa, sem a necessidade de processar e analisar grandes volumes de texto.
Recuperação Hierárquica Automática com Integração (Hierarchical Automerge Retrieval)
Você tem um documento pai, dentro dele você pode ter capítulos e dentro desses capítulos você tem pedaços desses capítulos (chunks).
Se você tiver 2 chunks dentro de um parágrafo que acertou, você pode querer retornar o parágrafo inteiro ao invés de devolver só os dois pedaços assinalados em vermelho na illustração.
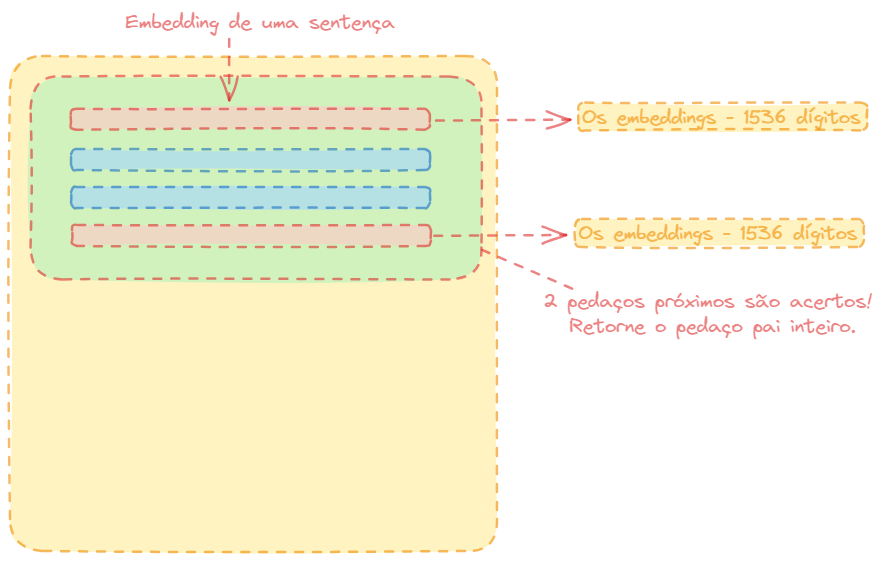
Recuperação Hierárquica Automática com Integração
Isso implica que toda a secção do documento é relevante.
Isso acaba nos dando uma estrutura em árvorem que tem no nível superior da árvore o pai e então você tem um próximo nível da árvore e finalmente você tem os nós folhas.
Se houver mais que um determinado número de nós folhas que são atingidos, então você subirá um nível na árvore, para retornar o pai inteiro desses nós.
Dependendo do tamanho da sua base de conhecimento, a criação desse índice vetorial pode levar algum tempo, pois você precisa transformar cada pedaço de texto em um embedding.
Por isso, precisamos de um armazenamento persistente para esses índices, ou seja, os embeddings, para que não precise ser recriado toda vez.
Armazenamento dos Embeddings
No código vamos salvar esses embeddings em arquivos JSON.
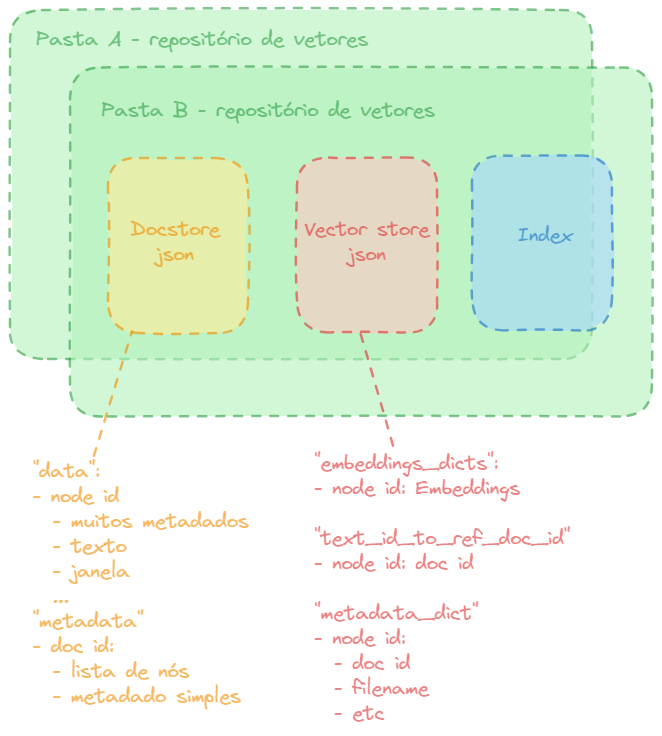
Armazenamento dos embeddings
Usar o índice Llama nos ajudará a salvar esses JSONs em vários documentos diferentes, veremos isso no código mais a frente.
Há 2 tipos de documentos particularmente úteis, o Doc Store e o Vector Store.
Doc Store
No Doc Store temos um id para cada nó, dentro dele tem um dicionário contendo um monte de metadados, o texto real que foi convertido para embeddings, assim como a janela, que é um contexto maior em torno do texto que foi incorporado, isto é, transformado em vetores numéricos, ou seja, em embeddings.
Esses embeddigs são retornados ao LLM.
Temos também alguns metadados e algumas informações de documentos de referência, cada um dos documentos tem um id e dentro de cada um desses documentos tem uma lista completa de nós pertencentes a esse documento, assim como metadados simples como: filename, etc.
Vector Store
Ele contém todos os embeddings, há um campo embeddings_dicts, é um dicionário de ids dos nós, com seus embeddings correspondentes.
Quando você executar a pesquisa semântica, você examinará esses embeddings para encontrar o mais semelhante e então você poderá procurar o id do nó e, a partir desse outro documento, recuperar a janela que precisa ser passada de volta ao LLM.
Depois de armazenar de forma persistente, toda vez que quiser usar, você pode simplesmente recuperar e trazê-lo de volta para uma ferramenta de mecanismo de consulta.
Você pode projetar suas ferramentas de consulta, empacotando as bases de conhecimento em diferentes ferramentas e assim quando você ativar seu mecanismo de consulta, você pode escolher e combinar essas diferentes ferramentas de mecanismo de consulta, dependendo do acesso que deseja dar ao usuário.
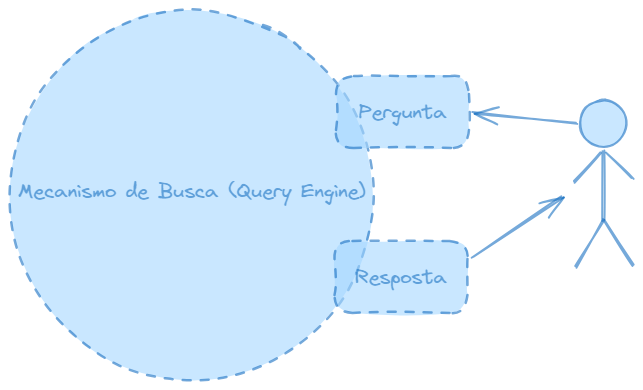
Perguntas e respostas do usuário
Quando o usuário chega com uma pergunta usando o mesmo modelo de embeddings, a pergunta é transformada em embedding.
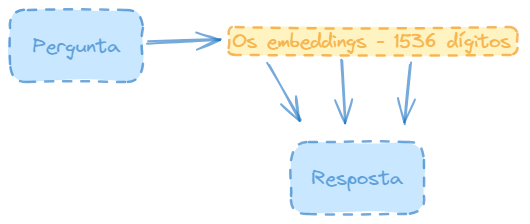
A pergunta é transformada em embeddings
Em seguida, pela similaridade de coseno nos índices, teremos um monte de resultados, que trazem de volta os embeddings armazenados no banco de embeddings que tem as correspondências mais próximas da pergunta como parte de sua estratégia de recuperação.
Você pode decidir por uma pesquisa gananciosa ou gulosa, então basta pegar a primeira, que é a correspondencia mais próxima, ou você pode querer passar para o LLM os top K principais acertos, que pode ser k=3, ou k=5.
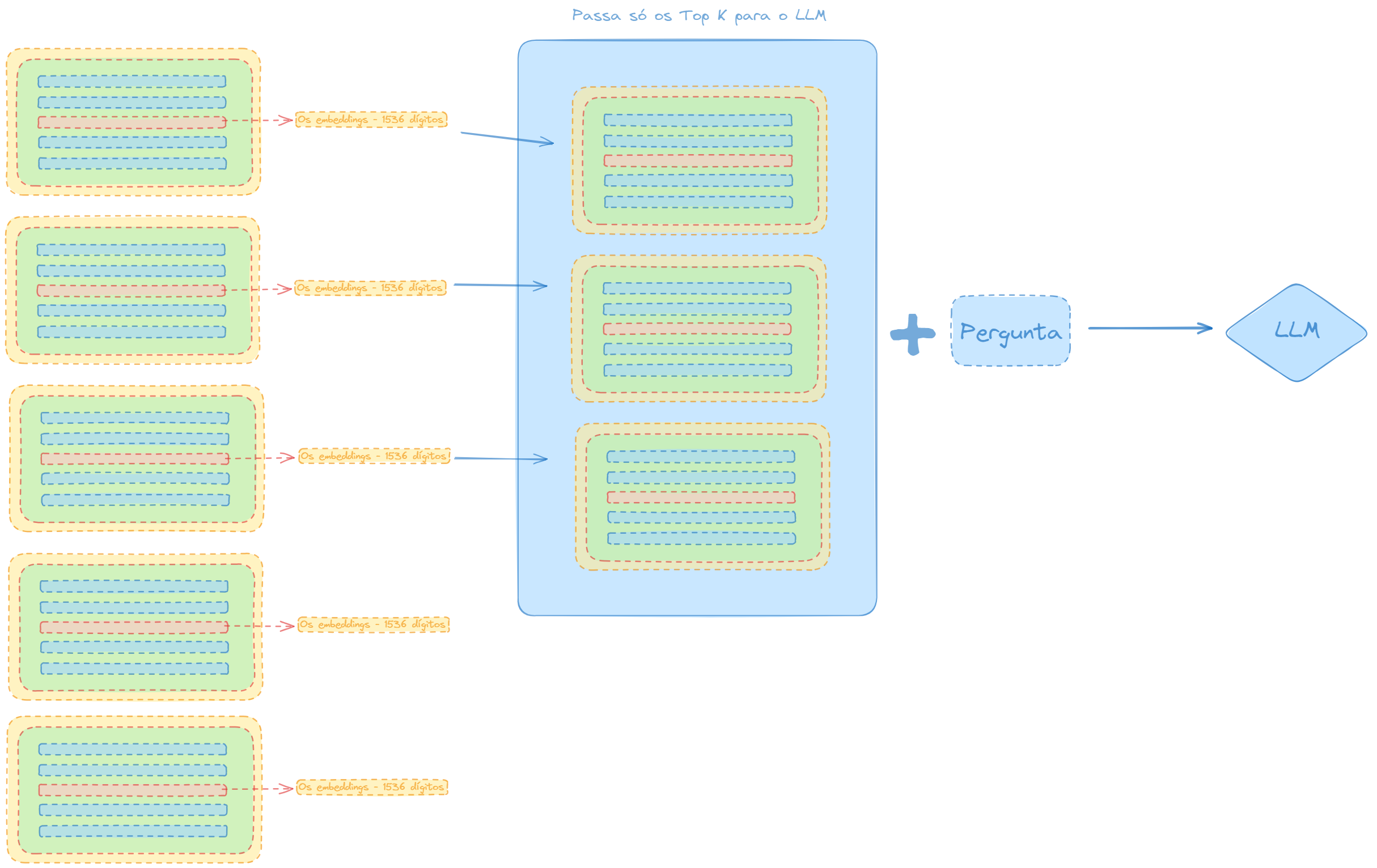
Passando só os top k e mais a pergunta para o LLM
Então, resumindo a figura acima, são recuperados os top K elementos, nesse caso, k=3, e passados junto com a pergunta, já incorporada em vetor numérico, ou seja, embeddings, de volta para o LLM, que gerará a resposta final para o usuário.
Prática
No exemplo prático, usaremos dois livros bem grandes, em formato txt, de código aberto, disponível no site https://www.gutenberg.org.
Um de 1800 sobre chá, história e mistério e um outro sobre a história da China.
Para testar, usaremos a pergunta abaixo:
question = “Something happened in the United States 10 years after the first American ships sailed for China which could have made it more expensive to purchase tea. what happened that year? Try to break down your answer into steps.”
O final da pergunta diz: “tente dividir a resposta em etapas.“.
Fizemos isso porque o modelo precisa de dois pedaços de informação para responder a pergunta, uma está no início do livro e outra no final.
Queremos testar com isso, se o modelo consegue recuperar informações das áreas relevantes do livro, para realmente nos dá uma resposta precisa.
Nessa frase: 10 years after the first American ships sailed for China ele precisa primeiro descobrir quando os primeiros navios americanos chegaram, para depois calcular 10 years after.
Em seguida terá que descobrir o que aconteceu naquele ano, que poderia ter causado o aumento dos preços do chá.
Pesquise no livro a frase “The first American ship sailed for China in 1784“.
Essa frase tá mais para o início do livro.
Algo aconteceu em 1784, pesquise agora 1784 no livro.
Veja que isso tá no final do livro.
Observe o parágrafo, e veja que a resposta correta seria os impostos do chá cobrados na época.