Ingestão de dados com o Flume
Link da documentação oficial do Hadoop:
http://hadoop.apache.org/
Link do meu Github:
https://github.com/toticavalcanti

DEFINIÇÃO
O FLUME É UM SERVIÇO DE INGESTÃO DE DADOS PARA COLETAR, AGREGAR E TRANSPORTAR GRANDES QUANTIDADES DE FLUXO DE DADOS (STREAMING), COMO POR EXEMPLO: ARQUIVOS DE LOG, EVENTOS, DADOS DE REDES SOCIAIS, SENSORES, ETC. DE VÁRIAS FONTES PARA UM ARMAZENAMENTO DE DADOS CENTRALIZADO (HBASE, HDFS…)
OUTRAS SOLUÇÕES
PARA ENVIAR DADOS STREAMING (ARQUIVOS DE LOG, EVENTOS, ETC.) DE VÁRIAS FONTES PARA O HDFS:
FACEBOOK’S SCRIBE − O SCRIBE É UMA FERRAMENTA IMENSAMENTE POPULAR QUE É USADA PARA AGREGAR E TRANSMITIR (STREAMING) DADOS DE LOG. ELE É PROJETADO PARA DIMENSIONAR UM NÚMERO MUITO GRANDE DE NÓS E SER ROBUSTO EM RELAÇÃO A FALHAS DE NÓS E DE REDE
APACHE KAFKA − O KAFKA FOI DESENVOLVIDO PELA APACHE SOFTWARE FOUNDATION. É UM AGENTE DE MENSAGENS DE CÓDIGO ABERTO. USANDO KAFKA, PODEMOS LIDAR COM FEEDS COM ALTA TAXA DE TRANSFERÊNCIA (HIGH-THROUGHPUT) E BAIXA LATÊNCIA.
O FLUME ATUA COMO UM BUFFER ENTRE OS GERADORES DE DADOS E O DESTINO FINAL.
VISÃO GERAL
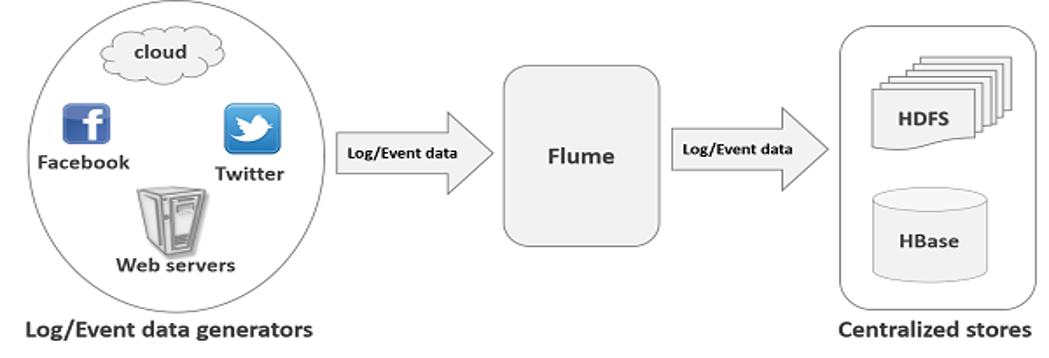
Flume visão geral
ARQUITETURA DO FLUME
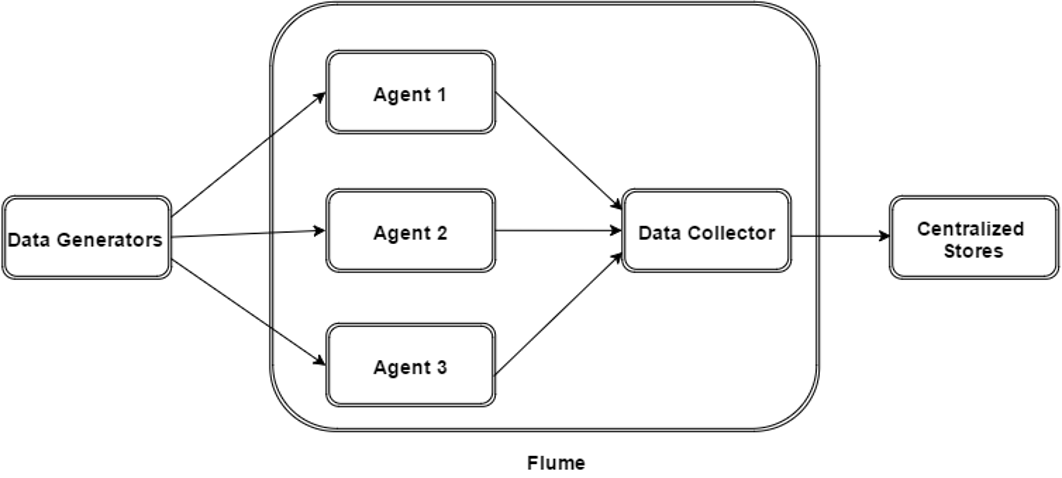
Arquitetura do Flume
EVENTO FLUME
UM EVENTO (EVENT) É A MENOR UNIDADE DE DADOS QUE TRANSITA NO FLUME
UM EVENT TEM UM CABEÇALHO (HEADER) OPCIONAL E O DADO EM SI (PAYLOAD)
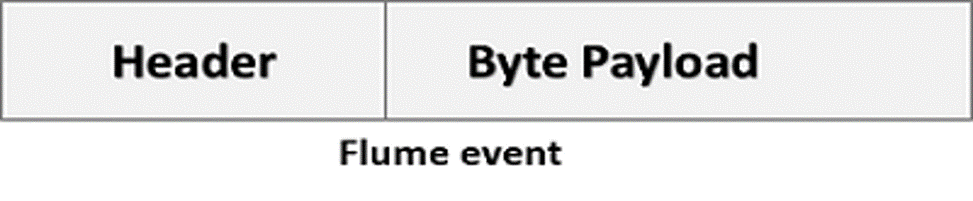
Evento Flume
AGENTE FLUME
UM AGENTE É UM PROCESSO INDEPENDENTE RODANDO POR TRÁS (DAEMON) EM UMA JVM
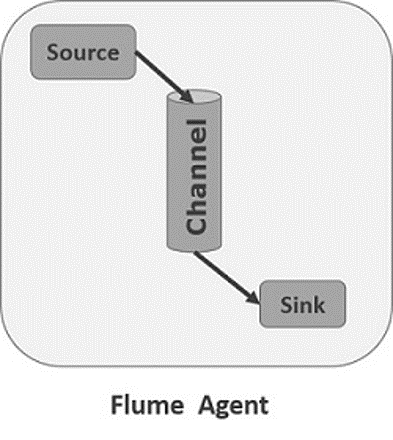
Agente Flume
UM AGENTE FLUME CONTÉM TRÊS COMPONENTES PRINCIPAIS:
- SOURCE – RECEBE DADOS DOS GERADORES DE DADOS E TRANSFERE-OS PARA UM OU MAIS CHANNEL NA FORMA DE EVENTOS FLUME.
- CHANNEL – É UM ARMAZENAMENTO TRANSITÓRIO QUE RECEBE OS EVENTOS DO SOURCE E OS PROTEGE ATÉ SEREM CONSUMIDOS PELO SINK. ATUA COMO UMA PONTE ENTRE OS SOURCE E OS SINKS.
- SINK – ARMAZENAM OS DADOS DE FORMA CENTRALIZADA NO HBASE E HDFS. CONSOME OS DADOS (EVENTOS) DOS CANAIS E OS ENTREGA AO DESTINO. O DESTINO DO SINK PODE SER OUTRO AGENTE OU UM ARMAZENAMENTO CENTRALIZADO (HBASE, HDFS)
MAIS ALGUNS COMPONENTES QUE DESEMPENHAM UM PAPEL VITAL:
- INTERCEPTORS – SÃO USADOS PARA ALTERAR/INSPECIONAR EVENTOS FLUME QUE SÃO TRANSFERIDOS ENTRE O SOURCE E O CHANNEL
- CHANNEL SELECTORS – EXISTEM DOIS TIPOS DE SELETORES DE CANAIS:
- DEFAULT CHANNEL SELECTORS – SELETORES DE CANAIS DE REPLICAÇÃO QUE REPLICAM TODOS OS EVENTOS EM CADA CANAL
- MULTIPLEXING CHANNEL SELECTORS – DECIDE PARA QUE CANAL ENVIAR UM EVENTO COM BASE NO ENDEREÇO NO CABEÇALHO (HEADER) DESSE EVENTO
- COLLECTORS – COLETA OS DADOS DOS AGENTES, OS DADOS DE TODOS OS COLLECTORS SÃO AGREGADOS E ENVIADOS PARA O ARMAZENAMENTO (HBASE, HDFS)
TIPOS DE FLUXO
- Multi-hop Flow – QUANDO EXISTEM VÁRIOS AGENTES E ANTES DE ATINGIR O DESTINO FINAL, UM EVENTO PERCORRE MAIS DE UM AGENTE
- Fan-out Flow − FLUXO DE DADOS DE UMA FONTE PARA VÁRIOS CANAIS.
- Replicating − OS DADOS SÃO REPLICADOS EM TODOS OS CANAIS CONFIGURADOS
- Multiplexing − OS DADOS SÃO ENVIADOS PARA UM CANAL SELECIONADO QUE É DEFINIDO NO CABEÇALHO DO EVENTO
- Fan-in Flow − FLUXO DE DADOS EM QUE OS DADOS SÃO TRANSFERIDOS DE MUITAS FONTES PARA UM CANAL
TRANSAÇÕES
PARA CADA EVENTO, OCORREM DUAS TRANSAÇÕES: UMA NO REMETENTE E OUTRA NO DESTINATÁRIO. O REMETENTE ENVIA EVENTOS PARA O DESTINATÁRIO. LOGO APÓS RECEBER OS DADOS, O DESTINATÁRIO FINALIZA SUA PRÓPRIA TRANSAÇÃO E ENVIA UM SINAL DE “RECEBIDO” PARA O REMETENTE
DEPOIS DE RECEBER O SINAL, O REMETENTE FINALIZA SUA TRANSAÇÃO. (O REMETENTE NÃO FINALIZA SUA TRANSAÇÃO ATÉ RECEBER UM SINAL DO DESTINATÁRIO)
CADA SOURCE TERÁ UMA LISTA SEPARADA DE PROPRIEDADES. A PROPRIEDADE DENOMINADA “TYPE” É COMUM A TODOS OS SOURCES E É USADA PARA ESPECIFICAR O TIPO DE SOURCE QUE SERÁ USADO
agent_name.sources.source_name.type = valueagent_name.sources.source_name.property1 = value agent1.sources.source1.port = 4144
CONFIGURAÇÃO SIMPLES DO AGENTE
FAZENDO UM PRIMEIRO TESTE COM O FLUME
BAIXE O ARQUIVO exemplo.conf NO MEU GITHUB E COLOQUE NA PASTA /etc/flume-ng/conf DA MÁQUINA CLOUDERA:
https://github.com/toticavalcanti/Curso_Hadoop/tree/master/Flume/Flume_primeiro_exemplo
ESSE ARQUIVO TEM O SEGUINTE CONTEÚDO:
#Start of exemplo.conf
# Nomeie os componentes neste agente
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Descreva / configure a fonte (source)
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Descreva o sink
a1.sinks.k1.type = logger
# Use um canal que armazene os eventos na memória
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Vincule o source e o sink ao canal
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
#End of exemplo.conf
AGORA INSTALE O TELNET NA MÁQUINA CLOUDERA COM O COMANDO:
yum -y install telnet
PARA ATIVAR O AGENTE, DENTRO DA PASTA /etc/flume-ng/conf DA MÁQUINA CLOUDERA DIGITE:
flume-ng agent -n a1 -c conf -f exemplo.conf
ABRA OUTRO TERMINAL E DIGITE O COMANDO ABAIXO
telnet localhost 44444
AGORA DIGITE NESSE TERMINAL QUALQUER TEXTO, VOCÊ VERÁ QUE O TEXTO DIGITADO NESSE TERMINAL APARECERÁ NO TERMINAL ONDE O FLUME FOI INICIADO.