Introdução ao Hadoop File System
Links da documentação oficial:
http://hadoop.apache.org/
Github:
https://github.com/toticavalcanti

Hadoop Map Reduce
HADOOP – INTRODUÇÃO
- É UMA PLATAFORMA DE COMPUTAÇÃO DISTRIBUÍDA VOLTADA PARA CLUSTERS E PROCESSAMENTO DE GRANDES VOLUMES DE DADOS
- É UM SISTEMA OPERACIONAL PARA BIG DATA
- CÓDIGO ABERTO
- CRIADO POR DOUG CUTTING DO GOOGLE LABS EM 2005
- CRIAÇÃO MOTIVADA PELO DESAFIO DA ESCALABILIDADE PARA CONSEGUIR INDEXAR BILHÕES DE PÁGINAS NA WEB
- O HADOOP FOI PROJETADO PARA PARALELIZAR O PROCESSAMENTO DE DADOS ATRAVÉS DE NÓS DE COMPUTAÇÃO, ACELERAR PROCESSAMENTOS E ESCONDER A LATÊNCIA.
HADOOP – MÓDULOS
- HADOOP COMMON – CONTÉM AS BIBLIOTECAS E ARQUIVOS COMUNS E NECESSÁRIOS PARA TODOS OS MÓDULOS HADOOP.
- HADOOP DISTRIBUTED FILE SYSTEM (HDFS) – SISTEMA DE ARQUIVOS DISTRIBUÍDO QUE ARMAZENA DADOS EM MÁQUINAS DENTRO DO CLUSTER, SOB DEMANDA, PERMITINDO UMA LARGURA DE BANDA MUITO GRANDE EM TODO O CLUSTER.
- HADOOP YARN – TRATA-SE DE UMA PLATAFORMA DE GERENCIAMENTO DE RECURSOS RESPONSÁVEL PELO GERENCIAMENTO DOS RECURSOS COMPUTACIONAIS EM CLUSTER, ASSIM COMO PELO AGENDAMENTO DOS RECURSOS.
- HADOOP MAPREDUCE – MODELO DE PROGRAMAÇÃO PARALELA E DISTRIBUÍDA PARA PROCESSAMENTO EM LARGA ESCALA.
HADOOP – FUNCIONAMENTO

Funcionamento Hadoop, cada nó é uma máquina diferente.

Divide o arquivo vermelho de 128 megas em dois blocos de 64.

Distribui as réplicas do bloco 1 do arquivo vermelho
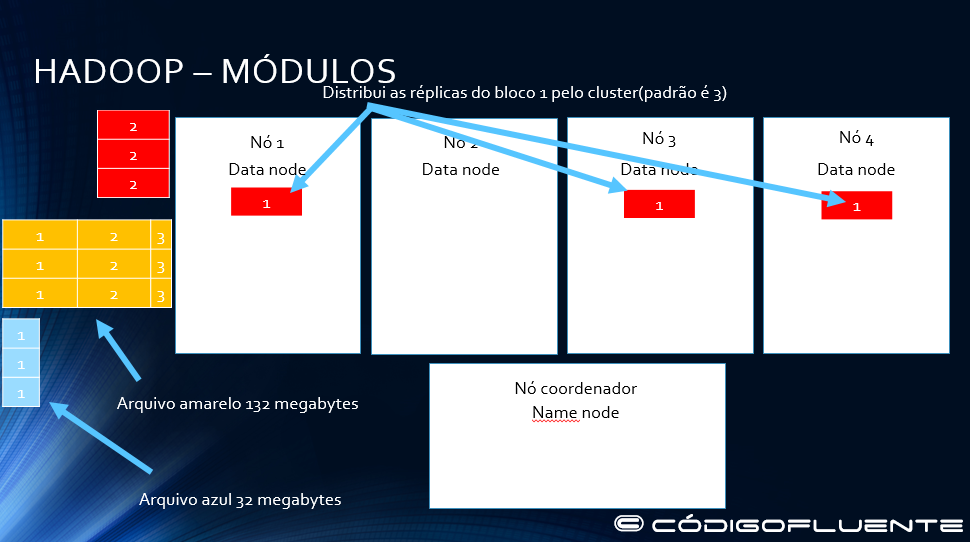
Distribui as réplicas do bloco 1 do arquivo vermelho

Distribui as réplicas do bloco 2 do arquivo vermelho
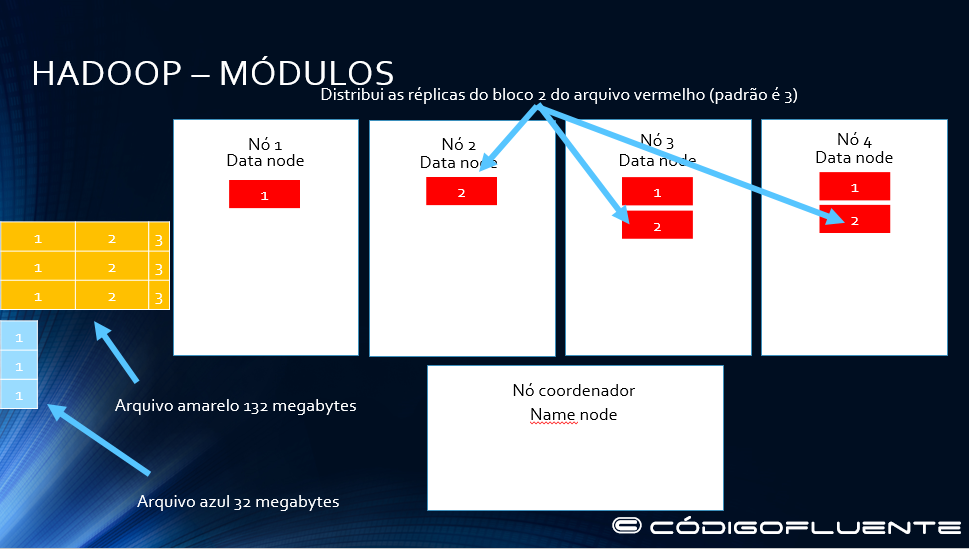
Distribui as réplicas do bloco 2 do arquivo vermelho

Distribui as réplicas do bloco 1 do arquivo amarelo
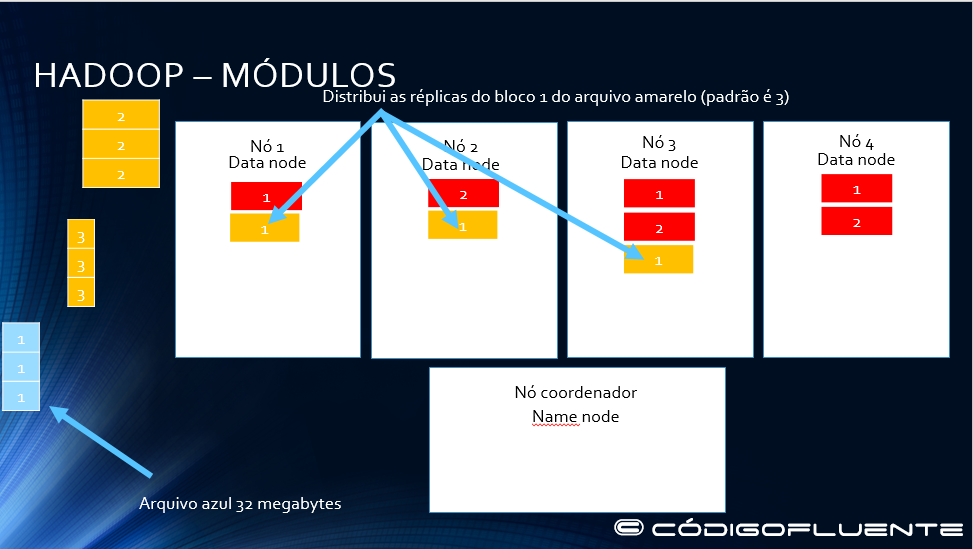
Distribui as réplicas do bloco 1 do arquivo amarelo

Distribui as réplicas do bloco 2 do arquivo amarelo
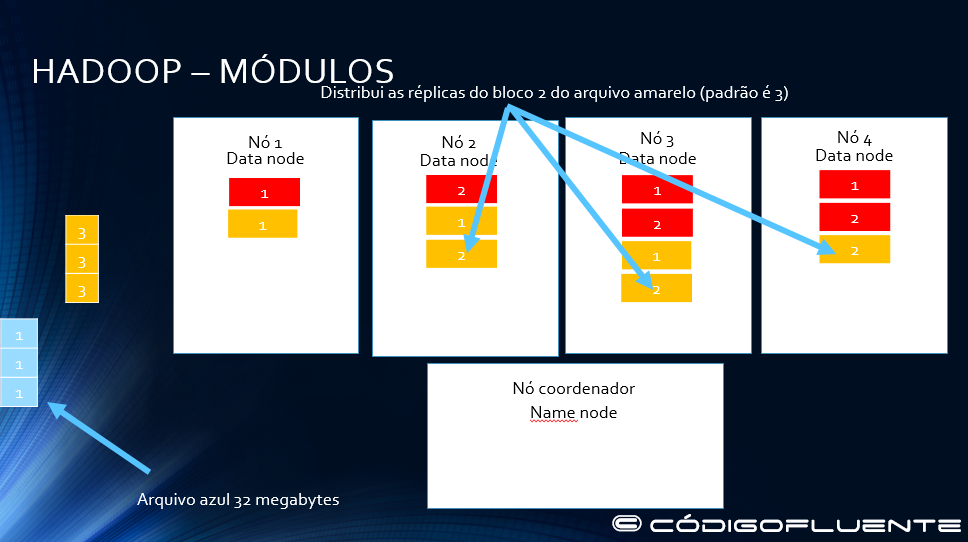
Distribui as réplicas do bloco 2 do arquivo amarelo
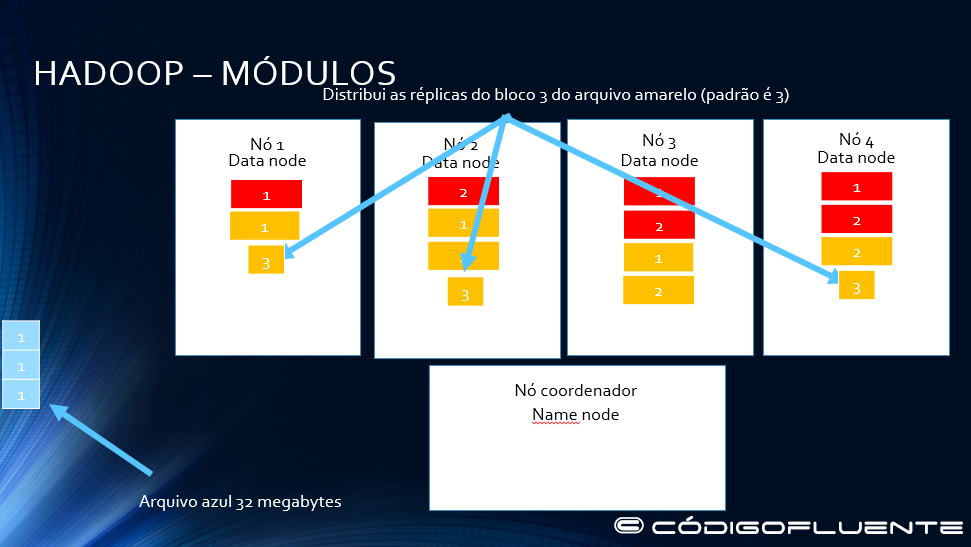
Distribui as réplicas do bloco 3 do arquivo amarelo

O arquivo azul será escrito no HDFS
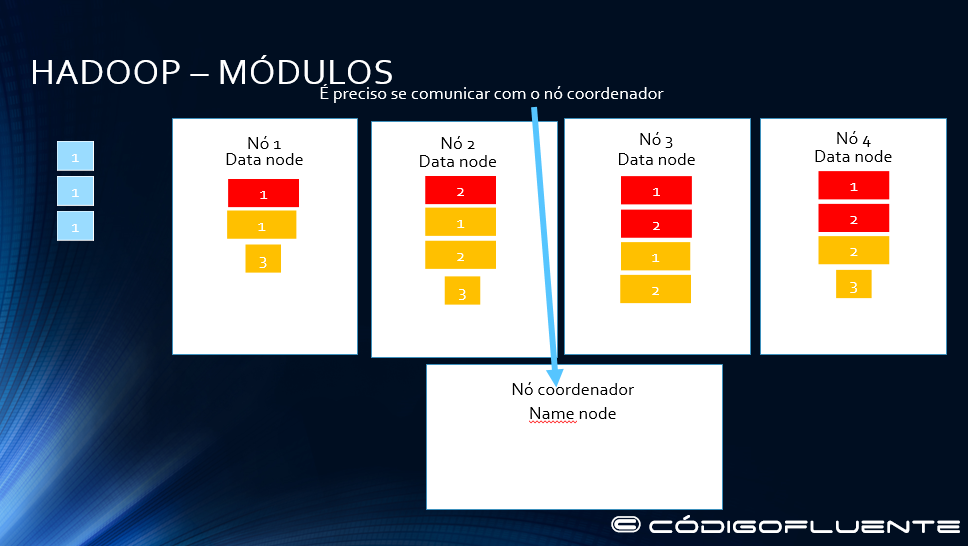
É preciso se comunicar com o namenode para saber onde escrever
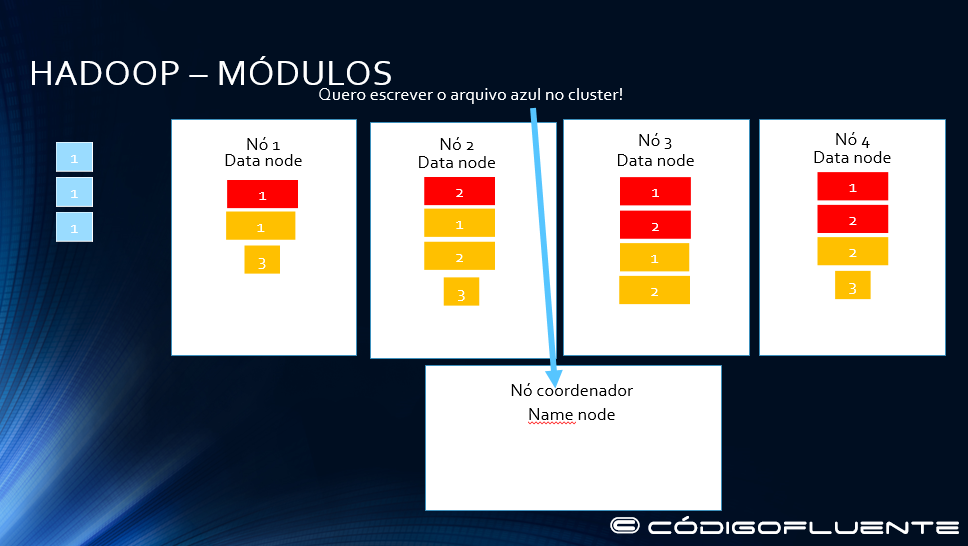
Comunicação com o namenode solicitando a escrita do arquivo azul

O name node responde: grave nos nós 1, 2 e 3

O cliente se comunica com o nó 1
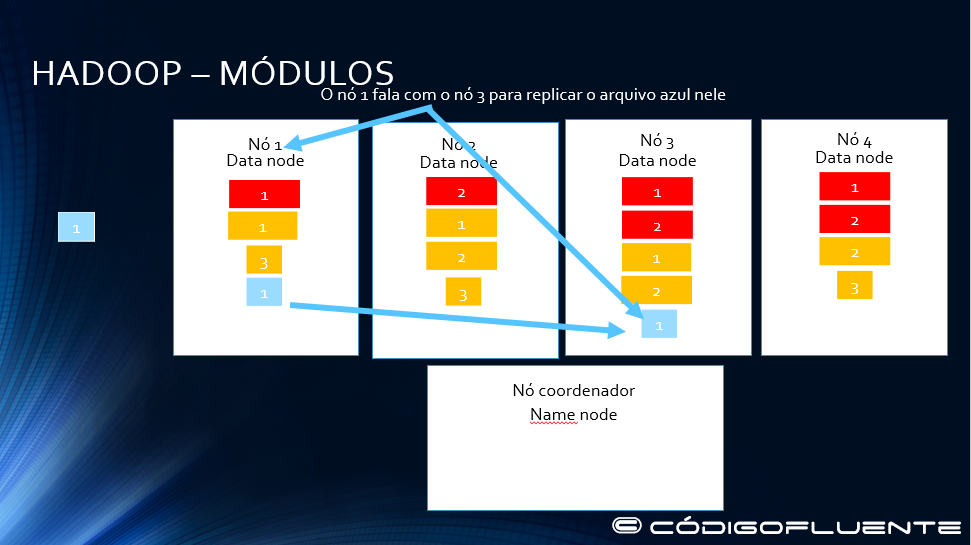
O nó 1 se comunica com o 3 para a réplica do bloco 1 do arquivo azul

O nó 3 replica o bloco 1 do arquivo azul no nó 4
HADOOP – LENDO ARQUIVO
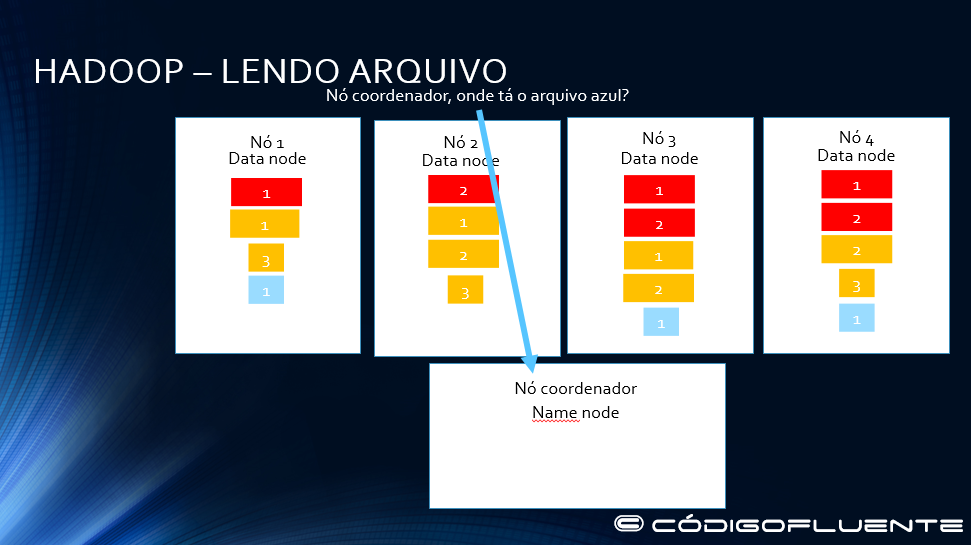
Lendo um arquivo, é preciso saber onde ele se espalha, por quais nós, é preciso se comunicar com o namenode
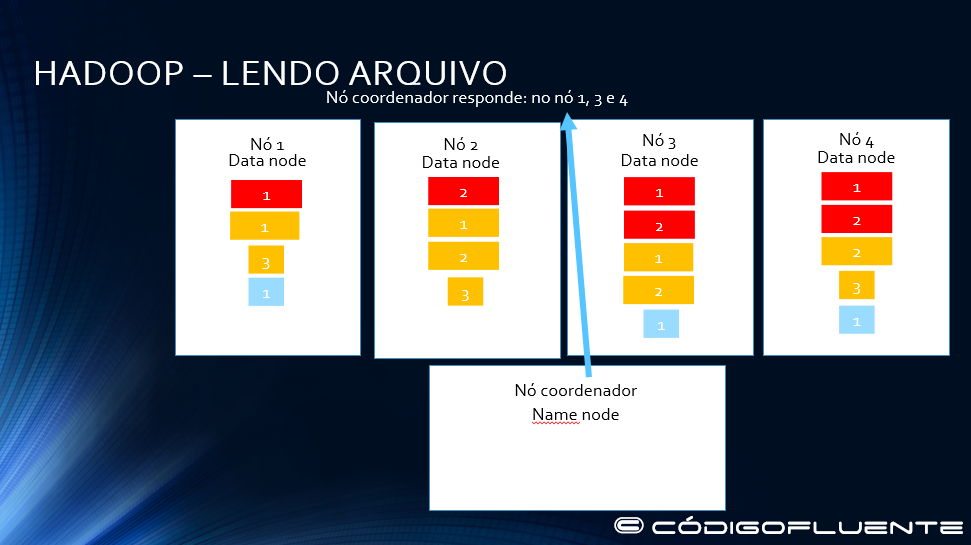
O namenode retorna dizendo que ele está nos nós 1, 3 e 4
- QUANDO SE QUER DESCOBRIR O QUE TÁ ACONTECENDO COM CLUSTER, É PRECISO SE COMUNICAR COM O NAMENODE
- POR EXEMPLO: ONDE POSSO LER O ARQUIVO AZUL?
- COM A RESPOSTA DO NAMENODE, A COMUNICAÇÃO PASSA A SER DIRETAMENTE COM O(S) DATANODE(S) QUE TEM O ARQUIVO AZUL
HADOOP – RESPONSABILIDADES

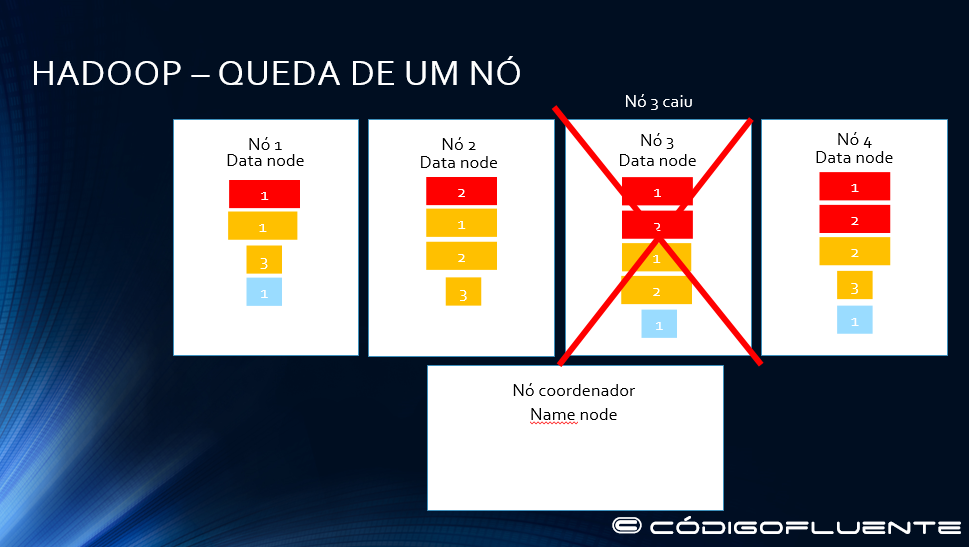
Queda do nó 3

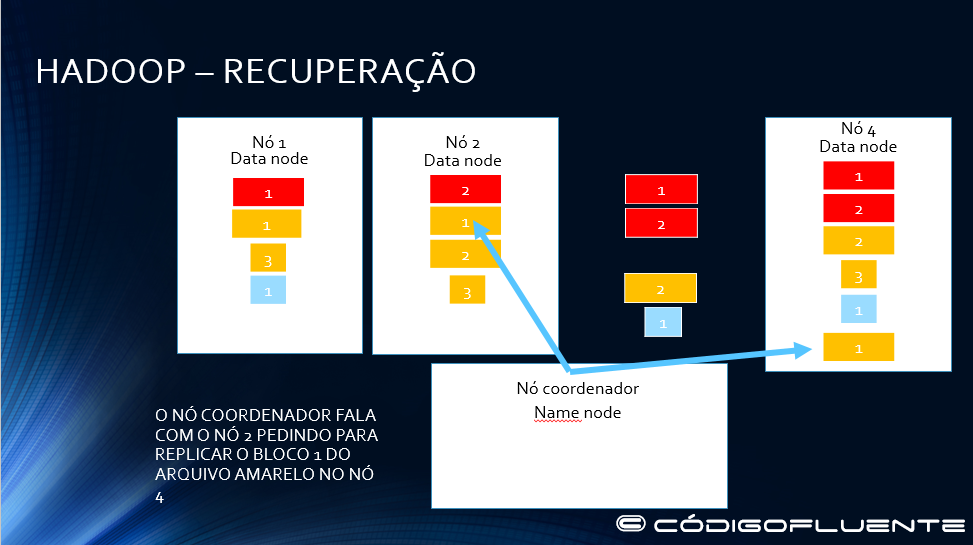
Namenode replica o bloco 1 do arquivo amarelo no nó 4
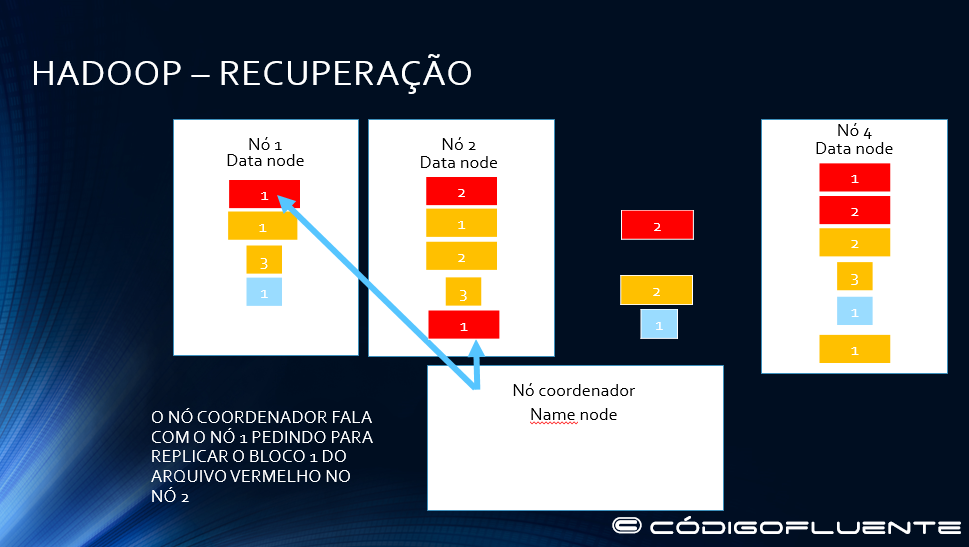
Namenode replica o bloco 1 do arquivo vermelhono nó 2
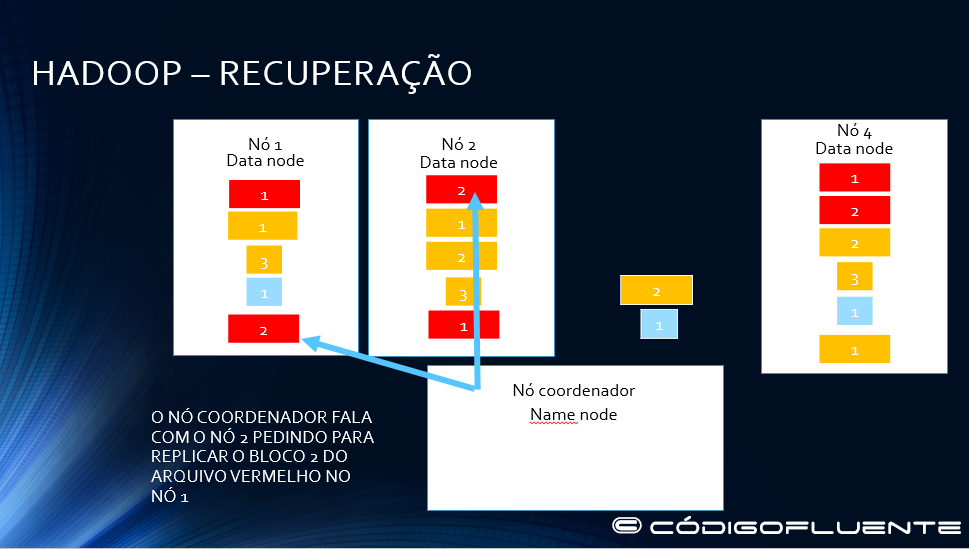
Namenode replica o bloco 2 do arquivo vermelho no nó 1
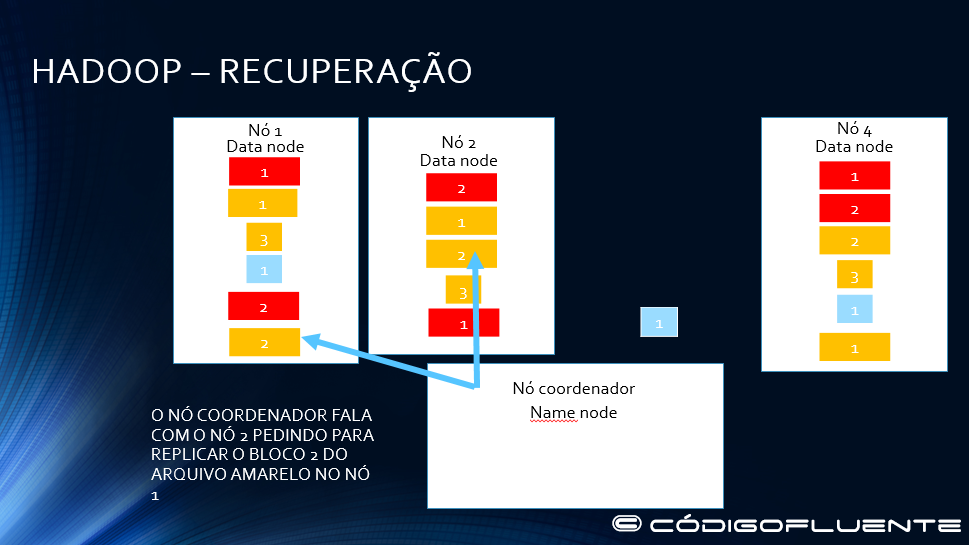
Namenode replica o bloco 2 do arquivo amarelo no nó 1
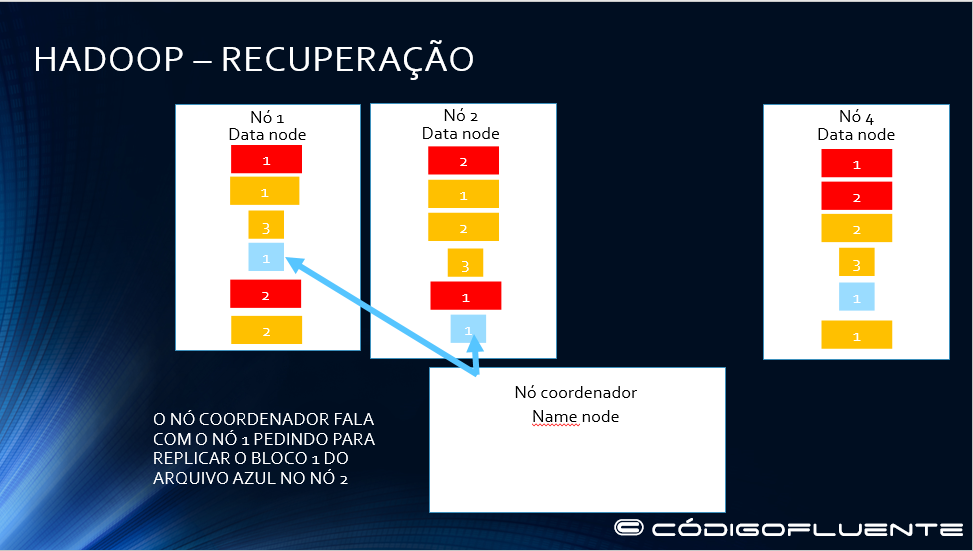
Namenode replica o bloco 1 do arquivo azul no nó 2
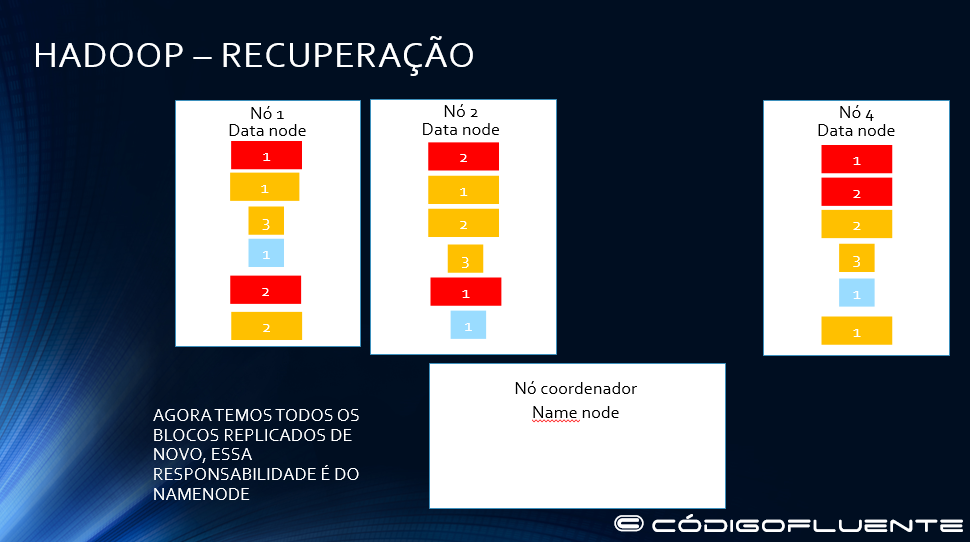
Agora todos os blocos de todos os arquivos estão replicados 3 vezes através das máquinas do cluster
HADOOP – RÉPLICAS
- AS RÉPLICAS SÃO NÃO SÓ PARA A SEGURANÇA DA INTEGRIDADE DOS DADOS, MAS TAMBÉM PELA LOCALIZAÇÃO DOS DADOS
- IMAGINEMOS QUE SE QUEIRA FAZER UM MAP-REDUCE NO ARQUIVO AZUL, COMO ELE TÁ NOS NÓS 1, 2 E 4, O TRABALHO DE MAP-REDUCE DEVERÁ OCORRER PREFERENCIALMENTE NESSES NÓS
- NO MAP-REDUCE, O PROCESSAMENTO É LEVADO AOS DADOS E NÃO OS DADOS AO PROCESSAMENTO