
Curso de Data Science Aula 01 – Data Science – R – Conhecendo a plataforma Kaggle. O que é o Kaggle? É uma plataforma fundada em 2010 para competições de modelagem preditiva e analítica. Empresas e pesquisadores postam seus dados e estatísticas para que mineradores, analistas e cientistas de dados de todo o mundo possam […]

Curso de Data Science Aula 03 – Data Science – R – Caso do Titanic – Kaggle Continuando com o problema do Titanic proposto pelo Kaggle. A ideia agora é juntar os dois conjuntos ( titanic.train e titanic.test) em uma variável titanic.full, mas para poder fazer isso, é preciso criar um campo nos dois conjuntos, […]

Curso de Data Science Aula 05 – Data Science – R – Caso do Titanic – Kaggle Continuando com o problema do Titanic proposto pelo Kaggle. Na última aula foi criado o campo Survived no titanic.test e atribuído valor NA ao campo, em todos os registros do titanic.test, agora vamos juntar o titanic.train e o […]

Curso de Data Science Aula 06 – Data Science – R – Caso do Titanic – Kaggle Continuando com o problema do Titanic proposto pelo Kaggle. Agora que o campo Embarked está devidamente limpo, vamos olhar agora para o campo Age. Rodando: table(is.na(titanic.full$Age)) Saída: FALSE TRUE 1046 263 Existem 263 registros sem a informação age […]

Curso de Data Science Aula 07 – Data Science – R – Caso do Titanic – Kaggle Continuando com o problema do Titanic proposto pelo Kaggle. Já limpamos os campos Embarked e Age, agora vamos limpar o campo Fare. Verificação agora do campo Fare (tarifa): table(is.na(titanic.full$Fare)) Saída: FALSE TRUE 1308 1 Ou seja, 1 registro não […]

Curso de Data Science Aula 08 – Data Science – R – Caso do Titanic – Kaggle Continuando com o problema do Titanic proposto pelo Kaggle. Agora que todos os registros tem a informação de Age, Embarked e Fare, vamos agora transformar algumas variáveis em variáveis categóricas, também conhecidas como qualitativas. Exemplos de variáveis qualitativas […]

Curso de Data Science Aula 09 – Data Science – R – Caso do Titanic – Kaggle Continuando com o problema do Titanic proposto pelo Kaggle. CONSTRUÇÃO DO MODELO Random Forest é um método de aprendizado sobre conjuntos de dados (ensemble learning) para construir modelos de classificação, regressão e outras tarefas; Gera múltiplas árvores de […]
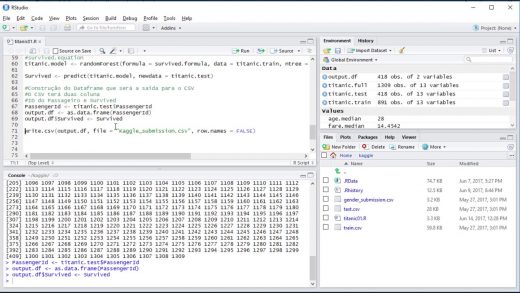
Curso de Data Science Aula 10 – Data Science – R – Caso do Titanic – Kaggle Continuação da aula 09, agora rodando os comandos no RStudio Continuando com o problema do Titanic proposto pelo Kaggle. CONSTRUÇÃO DO MODELO Random Forest é um método de aprendizado sobre conjuntos de dados (ensemble learning) para construir modelos […]
